

📢 본 문서에서는 MVCC 모델을 통해 소개한 Transaction ID(이하 XID)에 대해 자세히 알아보도록 하겠습니다. 우선 ①XID의 정의와 용도를 확인하고, ②부족한 XID를 극복하기 위해 PostgreSQL이 선택한 방법을 알아보도록 하겠습니다.
Transaction ID
XID 란?
우리는 미래에 일어날 사건에 대해 알지 못하지만 과거에 일어났던 사건들은 충분히 알 수 있습니다. 현실이 아닌 DBMS에서 일어나는 일련의 사건들을 트랜잭션이라고 부르며, 트랜잭션이 발생한 시점을 식별하기 위한 정보로 XID가 사용됩니다. 즉, XID란 일종의 시간 정보로 이해할 수 있습니다.
XID는 트랜잭션이 일어날 때마다 하나씩 증가하며, MVCC모델의 구현 및 읽기 일관성을 위해 사용됩니다.
XID 사용용도
트랜잭션이 발생할 때마다 증가하는 XID를 어디에, 어떻게 적용하여 사용하는지 궁금해질 수 있습니다. 시간 정보 와도 같은 XID는 아래와 같이 오브젝트를 생성하거나 데이터의 변경이 생길 때마다 그 시점을 기록하는 용도로 사용됩니다.
relfrozenxid: Object 생성 시점의 XID를 Object에 할당 (+ Vacuum 수행 시 시점 갱신)XMIN,XMAX: Row(레코드)가 입력되거나 변경된 시점의 XID를 Row단위로 할당
이처럼 오브젝트, 그리고 Row 단위로 할당되는 XID는 조회 시점의 XID와 비교하여 읽을 대상인지 아닌지를 판단하기 위한 용도로도 쓰이며, 너무 오래된 XID를 갖는 Object는 Vacuum의 대상이 되기도 합니다.
구조적인 한계와 보완 대책
부족한 XID
XID가 시간 정보로 사용된다는 것은 그 값 자체만으로 시점을 특정할 수 있는 기능이 내포되어 있음을 의미하기도 합니다. 마치 우리가 살고 있는 2022년이 미래에 다시 반복되지 않으리라는 확신과도 비슷합니다.
PostgreSQL의 XID와 비교 가능한 Oracle SCN의 표현 범위는 2^63(19c 기준)으로, 몇 천년 이상 사용 가능한 숫자를 표현할 수 있습니다. 제한은 있으나 사실상 그 수치에 도달할 리 만무하므로 잠정적으로 충분한 숫자라고 결론 내릴 수 있습니다.
- DB 인사이드 | PostgreSQL Vacuum - 1. MVCC 내용 中 -
각 레코드(row) 별로 4 Byte의 버전 정보(XID)를 두어 시점을 식별할 수 있도록 한다
하지만 PostgreSQL의 경우 데이터의 입력 및 변경 시 Row 단위로 XID를 할당해야 하므로 공간 사용 이슈가 발생할 수밖에 없습니다.
즉, 공간 절약의 측면까지 고려해 정의된 4 Byte의 XID값이 이번에는 표현 가능한 XID의 범위를 제약하는 결과를 초래하게 되었습니다. 4 Byte로는 약 43억의 XID밖에 표현할 수 없으며, 이는 TPS가 높은 시스템에서 불과 몇 달이면 모두 소진할 수 있는 수치입니다.
순환 구조
이처럼 절대적인 XID 개수가 부족한 구조적인 문제를 극복하기 위해서 PostgreSQL은 XID를 순환구조로 사용합니다.
이를 위해 아래 그림과 같이 현재 시점을 기준으로 총 XID(40억)의 절반(20억)에 대해서는 미래에 발생할 트랜잭션을 위해 사용될 예약된 XID공간(Newer)으로, 나머지 절반(20억)은 과거 발생했던 트랜잭션의 읽기 일관성을 보장하기 위한 XID공간(Older)으로 분류합니다.
📌 PostgreSQL의 실제 XID는 약 43억이며, Newer/Older 영역의 XID는 각각 약 21억이지만, 본 문서에서는 간략한 표현 및 쉬운 계산을 위해 각각 40억과 20억으로 표현했습니다.
순환 구조를 보다 쉽게 이해하기 위해 아래 그림을 살펴보도록 하겠습니다.
앞서 이야기한 Newer/Older 영역에 포함되는 XID는 고정되어 있지 않습니다. Newer/Older 영역은 단순히 고정된 창문과 같이(Window) 각각 20억 개의 XID를 바라보는 역할만을 수행합니다. 이와 반대로 XID는 트랜잭션이 발생할 때마다 컨베이어 벨트처럼 반시계 방향으로 움직이며, 레일의 끝에 도달하면 다시 Newer영역의 끝으로 추가되는 식으로 순환합니다.
즉 현재 시점에 따라 Newer/Older 영역에 포함되는 XID는 늘 변경되며, 동일한 이유로 XID값 자체의 크고 작음이 Newer/Older를 분류하는 기준이 되지는 않습니다.
Anti-Wraparound와 Data Freezing
여기까지 이해했다면, 다음과 같은 의문이 생길 수 있습니다.
40억을 주기로 하나의 Cycle을 도는 순환구조에서는 어느 순간 동일한 XID로 인한 시점 식별의 문제가 발생하지는 않을까?
예를 들어 XID=3인 시점에 입력된 후 변화가 없는 데이터가 있다고 가정해 보겠습니다.
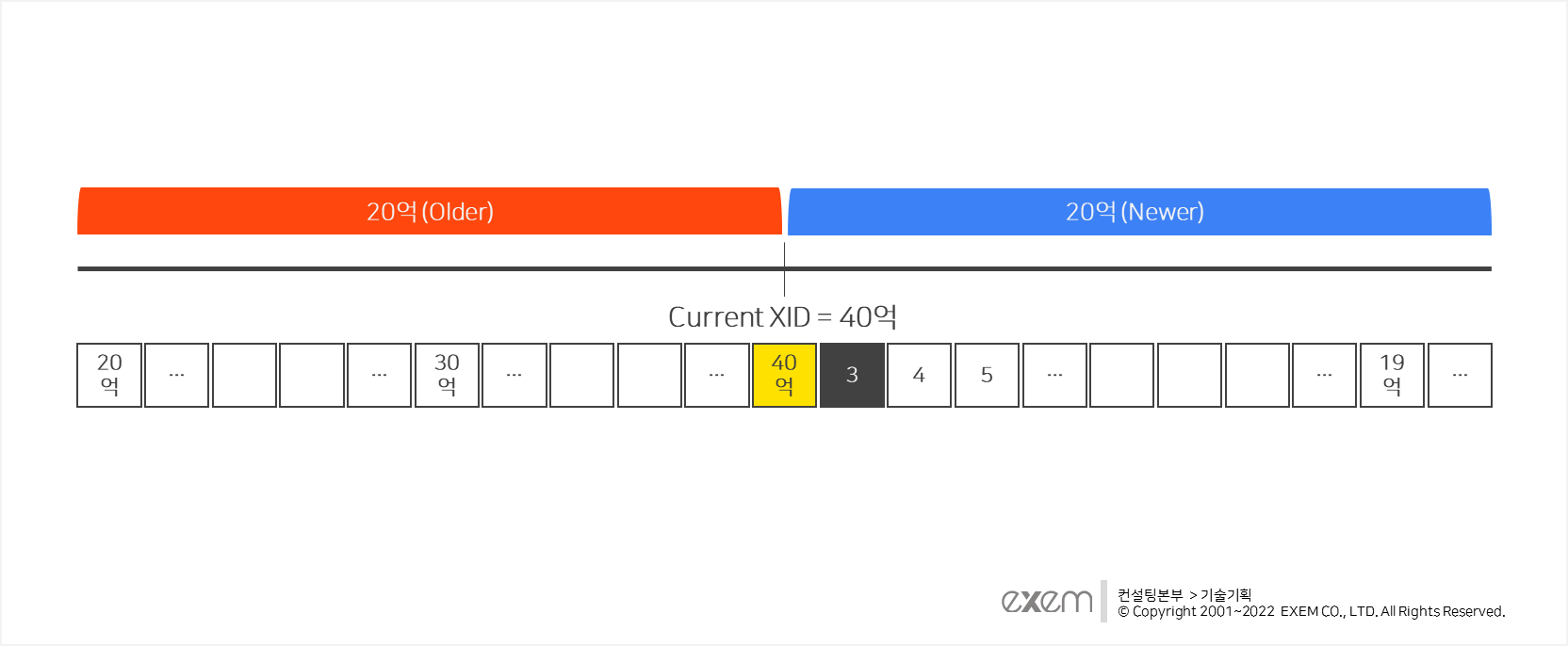
시간이 흘러 Current XID가 40억 시점이 됐을 때, XID=3에 입력된 데이터는 분명 과거에 입력되었지만 그 XID는 Newer 영역에 위치하고 있으므로 해당 XID를 갖는 데이터가 과거의 것인지 미래의 것인지 구분할 수 없는 문제가 생길 수 있습니다.
📌 그림에서 XID의 표현을 3부터 시작한 이유가 여기 있는데, 0,1,2는 특수한 의미를 지닌 예약된 값이기 때문입니다. 이 중, XID=2를 Frozen XID라고 하며, 실제 트랜잭션에 사용되는 일반 XID의 범위는 3~40억 이므로 Frozen XID는 항상 어떤 일반 XID보다 작음(오래됨)이 보장됩니다.
이러한 상황을 회피하고자 PostgreSQL은 “Current XID - 생성(입력) 시점의 XID”가 한 Cycle의 절반인 약 20억(=Older 영역에 위치하는 기간)을 벗어나기 전에 해당 자료들의 XID를 특수한 값으로 변경하는 작업을 수행하며, 또 하나 알 수 있는 사실은 40억 개의 XID 중 실제 사용 가능한 XID는 20억 개라는 것입니다.
이처럼 XID Wraparound를 피하기 위한 일련의 작업을 Data Freezing이라 부르며, 내부적으로 XID값을 Frozen XID라는 특수한 값으로 표시하여 영구적인 과거 데이터임을 표시하는 일련의 작업을 수행합니다.
이럴 경우 XID=3 시점에 입력되었던 데이터는 Current XID가 20억이 되기 전에 이미 Frozen XID로의 변경이 보장되므로 이후에 XID=3 시점에 입력되는 데이터와의 식별 문제에서 벗어날 수 있습니다.


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PostgreSQL Vacuum - 4. Visibility Map (0) | 2022.04.29 |
|---|---|
| DB 인사이드 | PostgreSQL Vacuum - 3. Age (2) | 2022.04.29 |
| DB 인사이드 | PostgreSQL Vacuum - 1. MVCC (2) | 2022.04.29 |
| DB 인사이드 | PostgreSQL Architecture - 4. 동작 원리 (0) | 2022.04.27 |
| DB 인사이드 | PostgreSQL Architecture - 2. Physical Structure (0) | 2022.04.27 |




댓글