
1편에서는 array의 생성 방법과 타입 확인, 텐서 차원 등을 실습해 보았다면, 2편에서는 array를 직접 적용하여 실습해 보고자 한다.
2-4. numpy 인덱싱, 슬라이싱, 전치행렬
2-4-1. 인덱싱
인덱싱은 Python 리스트와 동일한 개념으로 사용되고, ‘,’(쉼표)를 통해 각 차원의 인덱스에 접근이 가능하다. 그리고 Ndarray에서 원하는 좌표 또는 특정 데이터만을 선택하는데 유용하게 사용된다. 이때 인덱싱을 할 때 0번부터 인덱스가 시작하는 것을 주의하고, 원하는 축을 지정하려면 axis를 통해 선택할 수 있다. 인덱싱 종류로는 '특정 데이터만 추출', '슬라이싱', '팬시 인덱싱', '불리언 인덱싱' 등이 있다.
- 인덱싱 및 슬라이싱
'특정 데이터만 추출'은 말 그대로 원하는 위치의 인덱스 값을 지정해서 해당 위치의 값을 받아내는 것이다. 1, 2차원 인덱싱 예시를 통해 확인할 수 있다.
- 1차원 배열 특정 데이터 추출 및 슬라이싱
원하는 특정 데이터를 추출할 수 있다.
arr = np.arange(10)
print(arr)
print(arr[2])
그림 2-4-1-1. 배열 생성 및 인덱싱
슬라이싱은 연속된 인덱스상의 배열을 추출하는 방식으로 범위를 지정해서 한 번에 리턴이 가능하다.
In [4]:
print(arr[3:7])
print(arr[3:7:3])
print(arr[-1])
그림 2-4-1-2. 슬라이싱
- 2차원 인덱싱
2차원 부터는 시각적으로 확인해보자. 일단 첫 번째 결과는 0번째 행에 4, 5번째 인덱스에 있는 값들을 리턴하게 되는데, 이유는 0부터 인덱스가 시작하기 때문이다. 그리고 슬라이싱을 할 때 맨 처음 시작하는 숫자부터 끝나는 값의 전 값으로 구간을 잡게 된다 (기존 반복문 범위를 정하는 것과 같이 n 이상 n 미만과 같은 의미임). 두 번째 결과는 4번째 행부터 끝까지와, 4번째 열부터 끝까지의 인덱스들을 전부 추출하겠다는 의미이다. 세 번째 결과를 보면 콜론만 쓰인 것을 볼 수 있는데, 전부 가져오겠다는 의미이며, 인덱스 2번째에 있는 열의 값을 가져오기 위해 적어줘야 된다 (쉼표를 사용하기 위함). 마지막 결과는 콜론을 두 번 쓴 것을 볼 수 있는데 기존 Python 반복문과 같이 스텝을 의미한다. 숫자 '2'이기 때문에 짝수 번째 인덱스들만 추출하게 된다.
In [6]:
arr = np.arange(36).reshape(6,6)
print(arr)
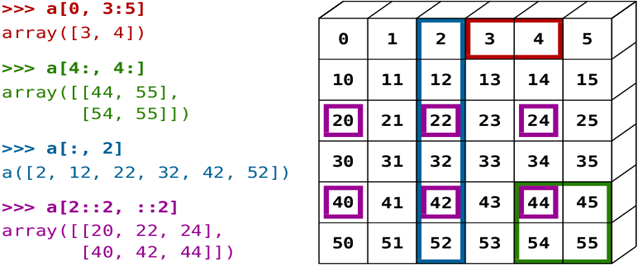
2-4-2. 불리언 인덱싱
불리언 인덱싱이란 배열의 각 요소의 선택을 불리언 마스크를 이용해서 지정하는 방식이다. 조건에 맞는 데이터를 가져오고, 참인지 거짓인지 알려준다.
- True, False 결과만 리턴 mask
비교 연산자만 적게 되었을 때, 조건에 따라 맞는 것은 True, 다른 것은 False로 성분이 구성된 배열을 반환한다. 이것을 Boolean array, 또는 마스크라고 한다.
arr2 = np.random.randint(-10,10,[20])
print(arr2)
print(arr2 <= 0)
Out [11]:
그림 2-4-2-1. 불리언 인덱싱
- 불리언 마스크 true 요소에 해당하는 인덱스만 조회
위에서는 마스크된 배열을 리턴한 결과를 봤다면 이번엔 마스크된 결과를 배열에 집어 넣어 원하는 값만 추출해 볼 수 있다. 인덱싱을 하듯 변수로 선언된 배열에 위와 같은 조건을 똑같이 넣으면 된다.
In [12]:
arr2[arr2 < 0]
이외 다른 연산자는 기존 Python 논리연산을 그대로 사용하면 된다.
2-4-3. 팬시 인덱싱
팬시 인덱싱은 정수나 Boolean 값을 가진 다른 Numpy 배열로 배열을 인덱싱하는 것을 의미한다. 불리언 값을 가진 배열을 사용하여 직관적으로 인덱싱이 가능하다.
In [14]:
arr = np.arange(0,10,1)
print(arr[[1,3,4,5]])
print(arr[[False,False,False,False,True,False,False,False,False,False]])
대괄호를 두 번 사용하지 않고, 인덱스만 추출하고 싶을 때는 np.where 함수를 이용하면 가능하다.
print(np.where(arr[:6]))
2-5. 전치행렬 및 축 변경
2-5-1. 전치행렬(transpose)
전치행렬은 행렬 계산, 주로 행렬 곱을 할 때 자주 사용한다. 이 때 행렬인 arr을 arr.T로 하거나 np.transpose(arr)과 같은 결과이다.
arr = np.arange(20).reshape(4,5)
print(arr)
print('------')
print(arr.T)
- 3차원 전치행렬
2차원 행렬과 같이 둘 다 축 변경이 가능하다. Np.transpose()의 경우 직접 축을 변경할 수 있지만, T의 경우 기존 행렬 크기에 맞게 내적을 할 수 있게끔 축 변경이 되기 때문에 맨 앞 차원이 뒤로 가게 된다.
In [21]:
arr = np.arange(20).reshape(1,4,5)
print(arr)
print('-----')
print(arr.T)
print('-----')
print(np.transpose(arr))
Out [23]:
- 전치행렬 축 변경(swapaxes)
Transpose와 크게 다르지 않게 사용이 가능하다. 하지만 transpose의 경우 안에 인자 없이 사용을 해도 상관이 없지만 swapaxes는 안에 인자를 디테일하게 적어줘야 하는 차이가 있다.
arr = np.arange(20).reshape(1,4,5)
print(arr)
print('-----')
print(np.swapaxes(arr, 0, 1))
print('-----')
print(np.transpose(arr, (1, 0, 2)))
print('-----')
print(np.transpose(arr, (1, 2, 0)))
Out [26]:
2-6. 산술연산
Numpy는 기본적으로 행렬간의 사칙연산을 지원한다. 그래서 같은 배열을 계산하면 해당 위치에 있는 값들이 계산된다. 대신 shape이 같을 때만 발생한다. 이런 현상을 element-wise operations라고 한다. Python 리스트 타입과 Numpy 배열 및 계산 후 결과를 확인해보자.
2-6-1. Python 리스트와 numpy 비교
Python 리스트의 경우 덧셈 시 항목을 이어 붙이는 concatenate를 수행하게 된다. 그리고 Python 리스트 간의 다른 연산은 허용하지 않는다.
list1 = [1,2,3,4]
print(list1 + list1)
arr1 = np.arange(4)
print(arr1 + arr1)
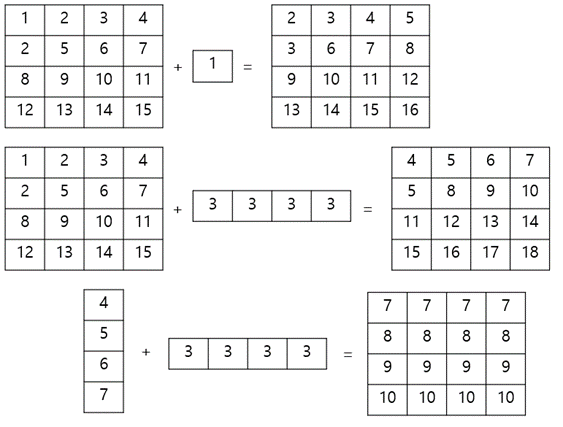
이때 스칼라 인자가 포함된 산술 연산을 할 경우 모든 원소에 스칼라 인자가 적용되며, 추가적으로 곱셈과 나눗셈은 자연수만 가능하고 원소 복사를 의미한다.
In [33]:
arr2 = arr1 + 1
print(arr2)
print(arr2 * arr2)
print(arr2 / arr2)
Python 리스트의 경우 산술연산을 지원하지 않기 때문에 위와 같은 방법으로 하면 오류가 뜬다.
print(list1 + 1)
이번 실습에서는 크기가 다른 배열 간에 연산이 가능한 것들을 살펴 봤는데, 이를 브로드 캐스팅이라고 한다.
- 브로딩 캐스팅에 대한 자세한 조건
1. 멤버가 하나인 배열은 어떤 배열에나 브로드캐스팅(Broadcasting) 가능(단, 멤버가 하나도 없는 빈 배열을 제외)
ex) 4x4 + 1
2. 하나의 배열의 차원이 1인 경우 브로드캐스팅(Broadcasting) 가능
ex) 4x4 + 1x4
3. 차원의 짝이 맞을 때 브로드캐스팅(Broadcasting) 가능
ex) 3x1 + 1x3
2-7. universal function(유니버설 함수)
유니버설 함수란 범용적인 함수(ufunc) 즉, Python과 Numpy의 차이는 있을 수 있지만, 둘 다 가지고 있는 함수를 뜻한다. 하지만 Numpy에는 벡터화 연산이 가능한데, 벡터화 연산이란 반복문을 Numpy 배열 요소에 각각 적용하는 아이디어이다. 그렇게 되면 반복문을 사용하지 않아도 요소별 연산이 가능하며 빠르다는 장점이 있다. 그래서 반복문이 보인다면, 이를 Python에 있는 기능으로 사용하지 않으면서 벡터화할 수 있을지 고민하는 것을 권한다.
- 단항(1개의 배열에 대한) np.ufunc
| Abs, fabs | 각 원소마다 절대값 |
| Ceil, Floor | 각 원소마다 올림, 내림 |
| Modf | 각 원소의 몫과 나머지를 각각의 배열로 반환 |
| Rint | 각 원소의 소수자리 반올림 |
| Log, log10, log2, log1p | 로그 값을 취한다.(자연로그, 로그, 로그2, 로그(1+x) |
| Exp | 각 원소에서 지수함수를 계산 |
| Sqrt | 각 원소마다 루트를 씌운다. |
| Square | 각 원소마다 제곱 |
| Isnan | 각 원소가 숫자가 아닌지 boolean으로 리턴 |
| Isinfinite | 각 원소가 유한한 수인지 확인 |
| Logical_not | 각 원소의 논리 부정 값을 계산(== ~arr) |
| Sin, cos, tan | 각 함수의 값 계산 |
| Arcsin, arccos, arctan | 역 삼각함수 계산 |
- 이항(2개의 배열에 대한) np.ufunc
| Add(arr, arr), subtract(arr, arr), Multiply(arr, arr) | 두 배열에서 각 요소끼리 더하기, 빼기, 곱하기 |
| Divide(arr, arr), floor_divide(arr, arr), mod(arr, arr) | 두 배열에서 각 요소끼리 나눈 값, 몫, 나머지 |
| Power(arr or num, arr or num) | 각 요소의 타입에 따른 승 계산 |
| Maximum(arr, arr), fmax(arr, arr) Minimum(arr, arr), fmin(arr, arr) |
두 배열에서 각 원소끼리 비교 후 큰 값 리턴 두 배열에서 각 원소끼리 비교 후 작은 값 리턴 |
| Greater(arr, arr), greater_equal(arr, arr), less(arr, arr) | 각 배열에서 각 원소끼리 비교 연산 결과를 boolean으로 반환 |
| Copysign(arr, arr) | 첫 번째 배열의 요소에 기호를 두 번째 배열의 요소 기호로 바꿈 |
2-8. 난수 생성
다양한 종류의 효과적 표본을 뽑기 위해 주로 사용한다. 밑에 실습은 정규분포 형태의 난수 배열을 생성한다. 물론 정규분포 이외에 다양한 난수 생성이 가능하다.
In [38]:
samples = np.random.rand(100)
print(samples)
Out [40]:
하지만 난수 생성도 완전 랜덤이 아닌 난수 생성기의 시드값에 따라 정해진 난수를 생성하기 때문에 ‘유사 난수’ 라고도 불린다. 난수 생성기 시드값은 np.random.seed로 변경 가능하다.
In [41]:
print(np.random.rand(10))
np.random.seed(0)
print(np.random.rand(10))
- Random 함수 정리
| Seed(num) | 난수 생성기의 시드 설정 |
| Rand(num) | 0~1 사이의 값의 균등 분포값을 리턴 |
| Randn(num) | 가우시안 분포에서 분포값을 리턴 |
| Randint(num1, num2) | 주어진 값 사이에서 난수 추출 |
여러 함수들을 사용해보려면 https://codetorial.net/numpy/index.html 을참고해보도록 하자.
Chapter 1. Time Series 머신러닝을 위한 기초 선형대수 및 통계학부터 학습하고 싶다면 여기로!

기획 및 글 | AI 1팀 김기중
'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 2. Pandas 3편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
|---|---|
| Chapter 2. Pandas 2편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
| Chapter 2. Pandas 1편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
| Chapter 2. Numpy 1편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.07.27 |
| Chapter 1. 기초 선형대수 및 통계학 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.06.27 |




댓글