

앞서 MySQL의 InnoDB Architecture와 그 구성 요소들에 대해 알아보았습니다.
본 문서에서는 해당 내용을 바탕으로 MySQL의 Connection 생성 및 사용자 요청 처리, 주요 Thread의 동작 방식에 대한 내용을 InnoDB 스토리지 엔진 사용을 토대로 설명하도록 하겠습니다.
Connection 생성 과정
MySQL의 Connection 생성 및 동작방식은 InnoDB 외 다른 스토리지 엔진에서도 모두 동일합니다.
MySQL Server는 하나의 OS 프로세스로 실행되며, 내부적으로 여러 개의 Thread가 동시에 작업을 수행합니다. 이때, MySQL은 자체 Thread 구현 방식을 가지고 있지 않으므로 OS의 Thread 관리 방식에 의존하여 동작합니다.
MySQL의 Connection 생성과정은 Connection Pool Layer에서 Thread Cache를 통해 Thread를 할당받아 User Session을 구성합니다. 각 Session(Thread) 별로 Query연산을 수행할 수 있으며, 해당 Thread는 사용자(Client)가 Connection을 해제할 때까지 유지됩니다.
아래 그림은 Client가 MySQL Server에 Connection 요청을 하고 Thread를 할당받는 과정을 표현하고 있습니다. Client가 MySQL Server로 Connection 요청을 보내며, Connection 요청은 단순하게 TCP/IP 연결 메시지입니다.
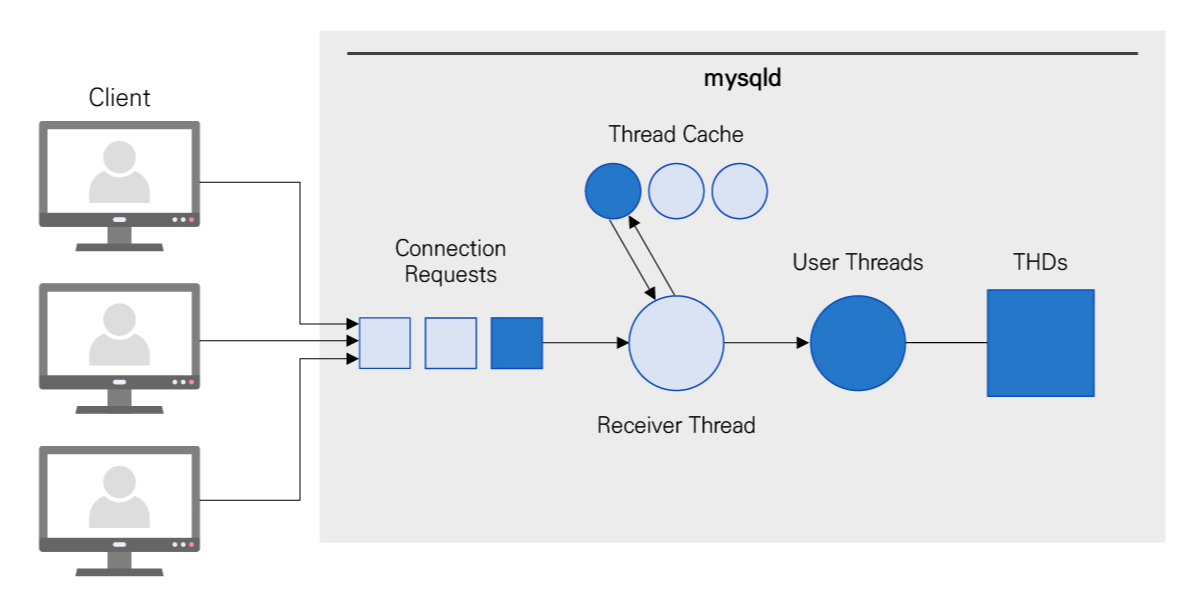
1. Client의 Connection 요청은 Connection Requests라는 Queue에 추가되며, Receiver Thread에 의해 순차적으로 처리됩니다. Receiver Thread의 역할은 User Thread를 생성하는 것이며, 이후의 사용자 요청 처리는 생성된 User Thread에 의해 수행합니다.
2. Receiver Thread는 새로운 OS Thread를 생성하거나 Thread Cache에 존재하는 미사용 OS Thread를 재사용하여 User Thread를 만듭니다.
3. User Thread는 Client의 권한 및 자격을 체크한 후, Client의 요청(Query)을 받아 처리합니다.
📢 THD란, 개별 Connection(Thread)마다 할당되는 THD Class의 객체를 의미합니다. 해당 객체는 Thread와 1:1로 매칭되며, 수행하는 Query 관련 정보나 Open Table 등의 메타정보를 갖고 있으며 sql_class.h에 정의되어 있습니다. 해당 객체 정보(THD)는 Connection이 맺어진 후 종료될 때까지 유지되며 재사용되지 않습니다. 또한, 하나의 Connection에서 수행되는 Query는 동일한 THD를 사용해야 하며 수행되는 Query에 따라 사용되는 메모리가 다릅니다.
4. User Thread는 SQL 처리과정을 통해 해당 요청(Query)를 처리하고 필요하다면 결과를 여러 번에 걸쳐 Client에 전달합니다.

5. 작업이 끝나면 User Thread는 다음 요청을 기다립니다.
6. Client가 COM_QUIT 명령을 보내거나 양 쪽 소켓이 닫히는 경우 관련 Connection은 해제됩니다. Connection이 끊기면 THD 할당은 해제되고, User Thread는 Thread Cache로 반환됩니다. Thread Cache에 여유 공간이 없으면 해당 Thread는 종료됩니다.

사용자 요청 처리 과정
User Thread는 사용자 요청(Query/Command)을 처리할때 Data를 MySQL의 Data 버퍼나 캐시로부터 가져옵니다. 버퍼나 캐시에 원하는 Data가 없는 경우 직접 디스크의 파일로부터 Data를 읽어와서 작업을 처리합니다.
사용자 요청은 크게 단순 읽기 작업(SELECT)와 변경 작업(DML)으로 분류할 수 있습니다. 두 요청은 모두 공통적으로 아래 2단계의 과정을 거치며, 변경 작업은 추가 과정(3~5번)을 거치게 됩니다.

1. User Thread는 MySQL의 InnoDB Buffer Pool에서 원하는 Data Page를 검색합니다.
2-1. 대상 Page를 Buffer Pool에서 찾을 수 없는 경우 디스크의 Tablespace 파일에 Access하여 Data를 Buffer Pool로 캐싱합니다.
2-2. Buffer Pool에 캐싱된 Page를 User Thread로 반환합니다.
(대상 Page가 Buffer Pool에 존재하는 경우 2-1 과정은 생략하고 바로 메모리에서 반환합니다.)

3. Page 변경 작업(DML)이 필요한 경우, Buffer Pool 내에서 Page를 수정합니다.
4-1. Page 수정 후, Log Buffer에 Redo Log를 작성합니다.
4-2. 트랜잭션 Commit이 발생하거나 Log Buffer가 가득 차는 시점에 디스크(Redo Log File)로 Flush합니다.
5. Buffer Pool의 수정된 Page(Dirty Page)의 경우 다음에 설명할 체크포인트 과정을 통해 디스크로 Flush 합니다.
CHECKPOINT
체크포인트 발생 시 Buffer Pool내의 변경된 Page를 디스크로 내려써 동기화 작업을 수행합니다. InnoDB 스토리지 엔진의 경우 체크포인트는 Sharp Checkpoint와 Fuzzy Checkpoint라는 두 가지 방식으로 분류할 수 있습니다.
Sharp Checkpoint
Commit 된 트랜잭션들의 모든 Dirty Page를 디스크에 Flush 하고, 가장 최근에 Commit 된 트랜잭션의 LSN(Log Sequence Number)을 기록합니다. Database가 정상 종료될 때나 Redo Log 파일의 순환하여 재사용해야 하는 경우에 InnoDB는 Sharp Checkpoint를 수행합니다.
Fuzzy Checkpoint
Fuzzy Checkpoint는 일반적으로 사용되는 체크포인트로, 모든 Dirty Page를 디스크로 Flush하지 않고, Dirty Page를 조금씩 디스크로 Flush 하고 그 위치를 관리하는 방식입니다. 두 개의 LSN(시작 시점, 종료 시점)을 기록함으로써 완료됩니다.
Fuzzy Checkpoint가 발생하는 유형은 다음과 같습니다.
- Master Thread Checkpoint
Master Thread는 1초 또는 10초마다 주기적으로 Flush List를 확인하여 일정 비율만큼의 Dirty Page에 대해 디스크로 내려씁니다. 비동기 방식으로 수행됩니다. - FLUSH_LRU_LIST Checkpoint
Free Page의 개수가 약 100개 이하로 - 여유 공간이 부족한 경우, LRU List의 Old 영역부터 일정 수치만큼 Scan 한 후 Dirty Page가 있으면 체크포인트 수행합니다. 이때, 체크포인트 대상 Page가 LRU List로부터 나왔기 때문에 해당 유형을 FLUSH_LRU_LIST라고 부릅니다. 5.6 버전부터는 Page Cleaner Thread에 의해 수행되며,innodb_lru_scan_depth만큼 LRU List에 대한 Scan을 수행합니다. - Async/Sync Flush Checkpoint
Redo Log File이 거의 가득 차서 Redo Log File을 사용할 수 없는 상황에서 발생하는 체크포인트 유형입니다. 이때 일부 Page를 강제로 디스크로 Flush 해야 합니다. Flush 후 Redo Log File을 재사용할 수 있습니다. MySQL 5.6 버전부터 Page Cleaner Thread에 의해 수행됩니다. - Dirty page too much Checkpoint
Dirty Page의 수가 너무 많은 경우 수행되는 체크포인트 유형입니다. Buffer Pool 공간 대비 Dirty Page 비율을 확인하여 특정 수치에 도달하면 체크포인트를 수행하며, 해당 수치는innodb_max_dirty_pages_pctSystem Variable를 통해 설정할 수 있습니다.
📢 Buffer Block List 종류는 다음과 같습니다.
- Free List : Free Page 정보를 관리하는 List
- LRU List (Least Recently Used) : 모든 Page List (LRU 관리)
- Flush List : 디스크로 기록되지 않은, 변경된 Page 정보를 관리하는 List
InnoDB Workflow
Query Execution Engine은 스토리지 엔진의 인터페이스를 호출하여 실행 계획에 따라 Query 실행하고 트랜잭션을 처리합니다.

📢 위 그림의 번호(1~7)는 전체적인 처리 과정에 따른 순서를 의미하는데, 이 중 변경 Data의 처리 과정(그림의 왼쪽, Data Flow)과 트랜잭션 로그 처리 과정(그림의 오른쪽, Log Flow)으로 나누어 각각에 대해 설명하겠습니다.
변경 데이터의 저장
1-1. 먼저 Query 조건에 맞는 Data가 Buffer Pool에 존재하는지 확인합니다.
1-2. Buffer Pool에 Data가 없다면 IO Thread가 디스크의 Data 파일에서 Buffer Pool로 해당 Data를 로드합니다.
2. 해당 Data를 변경하기 전에 현재 Data를 백업합니다.
- Undo Log에 Data를 저장함으로써 트랜잭션 Rollback이 가능해집니다.
- 불필요한 Undo Log는 Purge Thread에 의해 제거됩니다.
3. Undo Log를 생성 후, Query 내용에 따라 Buffer Pool 내의 해당 Data를 변경합니다. 이때 변경된 Data가 바로 디스크로 Flush 되지는 않으며 변경된 Page를 Dirty Page라고 합니다.
7. 이후, 특정 조건에 의해 체크포인트 발생 시 비로소 Dirty Page의 Data가 디스크로 Flush 됩니다.
- 먼저 Doublewrite Buffer에 Buffer Pool에 변경된 Page를 모아서 한 번에 Write 합니다.
- 마지막으로 Buffer Pool의 변경된 Page를 개별적으로 Data 파일에 Write 합니다.
📢 Doublewirte Buffer는 Buffer Pool로부터 Flush된 Page를 Data 파일에 쓰기 전에 저장하는 영역으로 Buffer라는 명칭과 달리 실제로는 디스크 영역에 존재합니다. Data 파일에 Page를 쓰는 도중 문제가 발생하면 Doublewirte Buffer을 통해 해당 Page를 복구할 수 있습니다.
트랜잭션 로그 관리(Redo Log & Binlog)
InnoDB는 미리 쓰기 로그(WAL: Write Ahead Log) 전략을 채택하므로, Data를 내려쓰기 전에 Log Buffer에 Redo Log(트랜잭션의 내용)을 먼저 기록합니다. 그리고 복제 구성 또는 특정 시점으로의 Data 복구 등에 사용하기 위해 Binlog(Data 변경사항과 소요시간 등을 포함)를 작성합니다.
Redo Log와 Binlog는 System Variable 값에 따라 Write&Flush 수행 시점이 달라질 수 있으며, Redo Log는 innodb_flush_log_at_trx_commit, Binlog는 sync_binlog로 설정합니다.
MySQL은 Redo Log와 Binlog 간의 데이터 일관성 문제를 해결하기 위해 2PC(Two-Phase Commit Protocol)를 사용하며, Prepare와 Commit으로 나누어 진행합니다.
4-1. Buffer Pool의 Data가 변경되면 Redo Log를 생성하여 Log Buffer에 추가합니다.
4-2. Redo Log 작성 후에 트랜잭션을 언제든지 Commit을 할 수 있는 prepare 상태가 되고, Log Buffer의 Redo Log를 디스크의 Redo Log File로 Flush 합니다.
5-1. 그리고 Data 변경사항 관련하여 Binlog Cache에 Binary Log(binlog)를 작성합니다.
5-2. 작성된 Binlog를 디스크로 동기화하고 Binlog Cache를 비웁니다.
6. Binlog 관련 정보를 Redo Log File에 기록하고 ACK와 Commit을 수행합니다.
📢 OS에서 사용자 공간의 Buffer Data는 일반적으로 디스크에 직접 쓸 수 없으므로, OS Cache를 거쳐야합니다. OS Cache에 먼저 기록한 후에 System Call을 통해 디스크의 로그 파일에 Flush합니다.
System Variable
| Parameter | Default Value | Range | Description |
| innodb_lru_scan_depth | 1024 | (64-bit) 100 - 2**64-1 (32-bit) 100 - 2**32-1 |
• InnoDB Buffer Pool에 대한 Flush 작업의 알고리즘 및 Heuristics(교수법)에 영향을 주는 System Variable입니다. • Buffer Pool 인스턴스 별로 Page Cleaner Thread가 Flush할 Dirty Page를 찾기 위해 Buffer Pool LRU Page List를 얼마나 멀리 Scan하도록 하는지 지정합니다. |
| innodb_max_dirty_pages_pct | 90 | 0 ~ 99.99 | InnoDB의 Dirty Page의 비율이 특정 수치이상 초과하지 않도록 Buffer Pool에서 Data를 Flush하도록 지정합니다. |
| innodb_flush_log_at_trx_commit | 1 | 0, 1, 2 | • 이 System variable을 통해 트랜잭션의 Commit 관련 로그를 Write&Flush 하는 시점을 조절할 수 있습니다. • 값에 따라 Data의 유실여부와 I/O 성능이 달라지므로 Data의 중요도와 성능을 고려하여 값을 설정해야 합니다. |
| sync_binlog | 1 | 0 ~ 4294967295 | • MySQL Server가 Binary Log를 디스크에 동기화하는 빈도를 제어합니다. • 0 : 디스크 동기화를 비활성화합니다. 운영체제에 의존하여 다른 파일처럼 때때로 디스크로 Flush합니다. 최상의 성능을 제공하지만 Data 손실 위험이 가장 큽니다. • 1 : 트랜잭션을 Commit하기 전에 디스크로 동기화할 수 있습니다. 가장 안전한 설정이지만 디스크 I/O가 증가하여 성능에 부정적인 영향을 미칠 수 있습니다. • N : 0 또는 1이 아닌 값으로 지정하면, N개의 Binary Commit Group이 수집된 후 디스크에 동기화됩니다. 값이 클수록 성능은 향상되지만 Data 손실 위험이 증가합니다. |


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PostgreSQL Setup - Installation (1) | 2022.08.25 |
|---|---|
| DB 인사이드 | PostgreSQL Setup - Version & Utility (0) | 2022.08.25 |
| DB 인사이드 | MySQL Architecture - 7. InnoDB : On-Disk Structure (0) | 2022.07.27 |
| DB 인사이드 | MySQL Architecture - 6. InnoDB : In-Memory Structure (0) | 2022.07.27 |
| DB 인사이드 | MySQL Architecture - 5. SQL 처리과정 (4) | 2022.06.30 |




댓글