

시작하며
본 문서에서는 HOT Update와 Single-page Vacuuming의 효과를 확인하기 위한 테스트를 진행합니다.
테스트 결과를 통해 Fillfactor 설정에 따라 어떤 차이가 있는지 확인해 보겠습니다.
📢 HOT Update, Single-page Vacuuming, Fillfactor에 대한 개념은 해당 시리즈의 1. Page와 관리 글에 설명되어 있으니 참고하시기 바랍니다.
TEST 환경 구성
설정
- 1만 건의 데이터를 가지고 있는 테이블 생성 (
autovacuum_enabled=false) - 100만 건의 Row Update 수행
- 수행 완료 후, 결과 확인
- Fillfactor값을 100→75→50→30으로 변경하며 동일 과정 반복
참고 Script
1) 테스트 데이터 생성
## TEST Table 생성
create table test_emp (
empno numeric(5,0) NOT NULL,
ename character varying(10),
job character varying(9),
mgr numeric(5,0),
hiredate timestamp(0),
sal numeric(7,2),
comm numeric(7,2),
deptno numeric(2,0),
sido_nm character varying(100)
)
with (fillfactor=100) ; -- fillfactor 옵션은 TEST 케이스에 따라 70, 50, 30 순으로 변경하여 진행
## TEST Table에 Index 생성
create index test_emp_pk on test_emp(empno) ;
## Autovacuum이 TEST 결과에 영향을 주지 않도록 옵션 변경
alter table test_emp set(autovacuum_enabled=false) ;
## Data 1만건 입력
insert into test_emp
select i, chr(65+mod(i,26))||i::text||'NM'
,case when mod(i,10000)=0 then 'PRESIDENT'
when mod(i,1000) = 0 then 'MANAGER'
when mod(i,3)=0 then 'SALESMAN'
when mod(i,3)=1 then 'ANALYST'
when mod(i,3)=2 then 'CLERK'
end as job
,case when mod(i,10000)= 0 then null
when mod(i,1000)= 1 then 10000
when i >= 9000 then 1000
else ceiling((i+1000)/1000)*1000
end as mgr
, current_date - i
, trunc(random() * 10000) as sal
, trunc((random() * 10000)*random()*10)::float as comm
, mod(i,12)+1 as deptno
, case when mod(i,3) = 0 then 'gangwon'
when mod(i,3) = 1 then 'busan'
else 'seoul'
end as sido_nm
from generate_series(1,10000) a(i) ;2) Update 수행
## Update 요청 - 각 1000건씩 10개의 Query로 분류하여 동시 수행 -> 총 100만건 Update까지 반복
--Update1
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 1 and 1000 ;
--Update2
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 1001 and 2000 ;
--Update3
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 2001 and 3000 ;
--Update4
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 3001 and 4000 ;
--Update5
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 4001 and 5000 ;
--Update6
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 5001 and 6000 ;
--Update7
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 6001 and 7000 ;
--Update8
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 7001 and 8000 ;
--Update9
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 8001 and 9000 ;
--Update10
update test_emp
set comm = (select trunc(sal*random()*10)::numeric )
where empno between 9001 and 10000 ;3) 테스트 결과 확인
select c.oid::regclass::text AS table
, c.reloptions
, c.relpages as table_page
, (select relpages from pg_class where relname = 'test_emp_pk') as index_page
, c.reltuples
, p.n_tup_upd
, p.n_tup_hot_upd
, round(coalesce((p.n_tup_hot_upd::numeric / nullif(p.n_tup_upd::numeric,0)) ,0) *100,1) as hotratio
, pg_stat_get_dead_tuples(c.oid) AS dead_tuple
, pg_size_pretty(pg_table_size(c.oid)) as table_size
, pg_size_pretty(pg_indexes_size(c.oid)) as index_size
, p.n_dead_tup
, p.autovacuum_count
from pg_class c , pg_stat_user_tables p
where 1=1
and c.relname = 'test_emp'
and c.relname = p.relname;
### WAL Check
select pg_current_wal_lsn () ; -- Update 전/후 lsn 확인
select pg_wal_lsn_diff('4/8514E818','4/74A8DFA0') /1024/1024 ; -- Update 전/후 lsn 차이 계산 (WAL 발생량)
결과 분석
1. Data 처리 성능
우선, 수행한 Update Query에 대한 성능 분석을 해보도록 하겠습니다.
성능은 두 가지 지표를 통해 확인할 수 있는데, 첫 번째는 100만 건의 Tuple을 처리하는 데 걸린 총시간을 측정하는 것이며, 두 번째는 초 당 몇 건의 요청(Query)을 완료하였는지, “Throughtput/sec” 결과를 확인하는 방법입니다.

위 결과를 보면, Update가 지속적으로 발생하는 상황에서는 설정된 FillFactor값이 작을수록 Update 처리속도가 빠르며 (Time), 같은 시간 동안 훨씬 더 많은 양의 Data를 처리할 수 있다는 것을 확인할 수 있습니다. (Throughtput)
📢 테스트를 통해 초당 176.6건의 요청(Query)을 수행하였다는 것을 확인하였으며, 이는 하나의 요청에서 1000 Rows Update하므로 176,600 Rows/sec 를 의미한다.
2. Update 처리 방식
두 번째로, 100만 건의 Data 중에서 HOT Update로 처리된 Tuple과 일반 Update로 처리된 Tuple의 수를 확인하여 HOT Update 수행 비율을 계산해 보겠습니다. HOT Update는 Update를 보다 효율적으로 처리하는 최적화 기법이므로, 이 비율을 활용하여 데이터베이스의 성능을 평가할 수 있습니다.
pg_stat_user_tables : n_tup_hot_upd, n_tup_upd
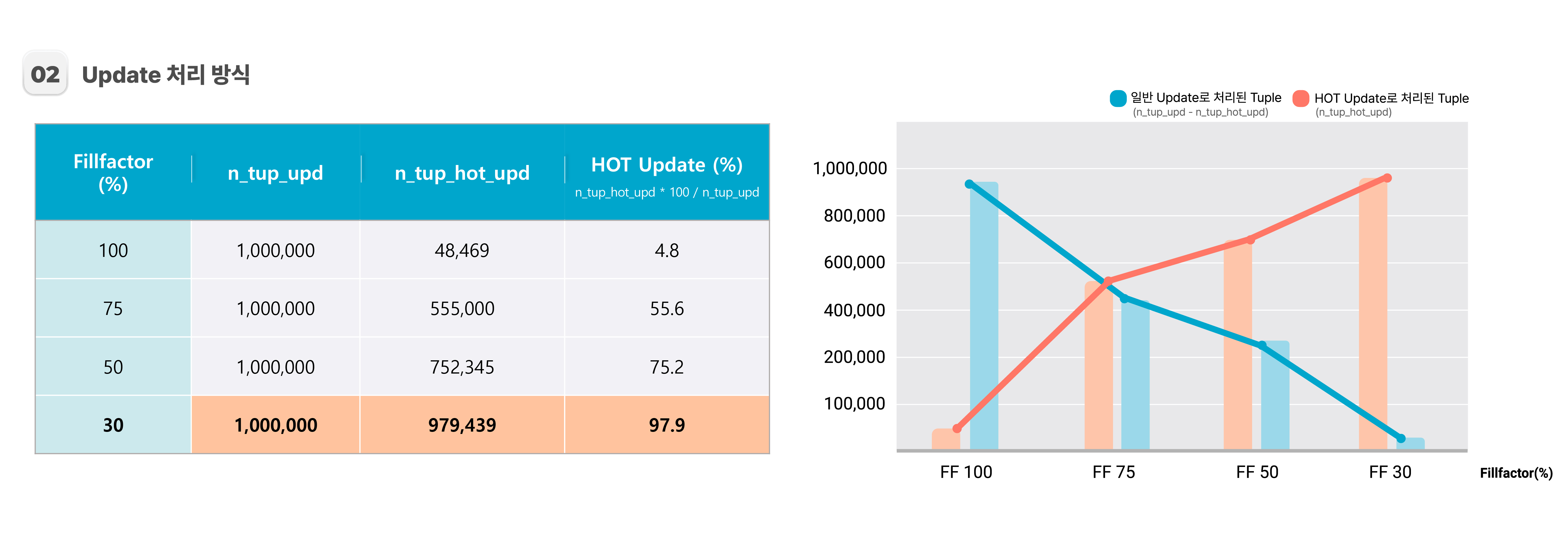
Fillfactor가 작을수록 Update를 위해 남겨둔 페이지 내 공간이 많으므로, HOT Update 처리 비율이 높을 것으로 쉽게 예상가능하며, 실제 TEST 결과에서도 Fillfactor값과 HOT Update 수행 비율이 반비례함을 알 수 있습니다.
3. Dead Tuple 발생량
Dead Tuple이란 말 그대로 변경 이전 버전의 Tuple을 의미하며, Dead Tuple 수치의 증가는 곧 공간의 비효율을 의미합니다. 이러한 Dead Tuple은 일반적으로 다음과 같은 Vacuum 작업을 통해 정리됩니다.
- Autovacuum이
OFF인 경우, Dead Tuple을 주기적으로 확인하여 Vacuum을 수동 관리해야 합니다. - Autovacuum이
ON인 경우, Autovacuum을 통해 Dead Tuple은 주기적으로 정리되므로 계속해서 증가하지는 않습니다. 하지만 Autovacuum이 그만큼 자주 수행되어 그로 인한 작업 부하가 추가될 수 있습니다.
본 TEST는 Vacuum관련 동작을 모두 억제한 상태(autovacuum_enabled=false)인데, 이러한 환경에서 Fillfactor값에 따른 Dead Tuple의 발생량을 확인해 보도록 하겠습니다.
pg_stat_user_tables : n_live_tup, n_dead_tup

결과를 살펴보면, TEST과정에서 특별히 Vacuum과 관련된 작업을 수행하지 않았지만, 실질적으로 Fillfactor값이 작을수록 Dead Tuple의 수치 역시 낮아졌다는 사실을 확인할 수 있습니다.
이는 SPV 발생 조건에 의해 Fillfactor값이 작을수록 더 자주 Single-page Vacuuming이 수행되었으며, 그 과정에서 Dead Tuple도 정리되었다고 해석할 수 있습니다.
📢 SPV 발생 조건
페이지 공간이 Fillfactor 값 이상으로 채워질 경우 Single-page Vacuuming이 수행됩니다.
4. Relation Size
이번에는 생성된 오브젝트 사이즈에 대한 Fillfactor 별 차이점을 확인해 보겠습니다.
사이즈 측정은 최초 데이터가 입력된 시점과 100만 건의 업데이트 발생한 이후, 총 2번에 걸쳐 확인을 하며, Fillfactor와 HOT Update에 따른 영향을 확인할 수 있습니다.
pg_class : relpages, pg_table_size(oid), pg_indexes_size(oid)

Table Size
우선, Update 이전의 테이블 사이즈를 보면 1만 건의 Data를 입력한 직후에 Fillfactor에 따른 테이블의 사이즈가 서로 다른 것을 확인할 수 있습니다. 이는 Fillfactor가 클수록(100%에 가까울수록) Update를 위한 여분의 공간을 적게 두며, 이는 결과적으로 적은 수의 페이지에 더 많은 데이터를 담았기 때문으로 볼 수 있습니다.
하지만 Update 이후의 결과를 보면, Fillfactor값이 작을수록 테이블 사이즈의 변동(증가량)이 작으며, 절대적인 크기는 Data를 입력한 시점과 정 반대로 역전되었음을 알 수 있습니다. 이는 Fillfactor값을 작게 설정한 경우, Update를 위해 남겨둔 공간이 많으며, Update 수행 시 페이지를 추가하는 대신 기존 페이지를 활용하기 때문입니다.
물론, 단순히 사전에 예약된 Update 공간을 활용한다는 사실만으로 이러한 극적인 사이즈의 변화를 설명하는 것은 불가능에 가깝습니다. 이러한 상황을 이해하기 위해서는 Dead Tuple이 정리되어 기존 공간을 재사용했다는 전제가 필요하며, 이는 앞서 설명한 SPV 발생에 의한 Dead Tuple 정리의 직접적인 효과라고 볼 수도 있습니다.
Index Size
반면, 1만 건의 Data를 입력한 후의 인덱스 사이즈는 테이블의 Fillfactor 설정과 상관없이 모두 동일(240 KB)합니다. 이는 테이블에 대한 Fillfactor는 테스트마다 변화를 주었지만, 인덱스의 경우 기본값(90)으로 적용되어 있기 때문입니다.
100만 건의 Update 수행 후 인덱스 사이즈를 확인해 보면, Fillfactor값이 낮은 테이블에 포함된 인덱스는 그 사이즈가 상대적으로 작습니다. 이는 HOT Update로 생성된 Tuple의 경우 추가적인 인덱스 엔트리를 생성하지 않기 때문인데, 동일한 양을 Update 처리해도 HOT Update 수행 비율이 높은 경우 관련 인덱스의 사이즈가 크게 증가하지 않는 이유입니다.
위 그래프를 통해 Update 작업 전 후 Relation Size(Table+Index)를 비교할 수 있습니다.
Insert 작업만을 수행하였을 경우에는 Fillfactor가 클 때 적은 페이지를 사용하므로 총사이즈가 적다는 것을 알 수 있고, Update 작업 수행이 반복될수록 Fillfactor가 클수록 더 많은 페이지를 사용하고 그로 인해 총 사이즈가 커지는 것을 확인할 수 있습니다.
5. WAL 발생량
📢 WAL은 트랜잭션에 대한 변경 로그를 저장합니다.
마지막으로, Update 작업 시 Fillfactor설정에 따른 WAL 발생량에 대해 확인해 보겠습니다.
WAL발생량은 Update 작업 이전과 이후의 WAL LSN 차이를 이용하여 확인할 수 있습니다. WAL 발생량을 통해 해당 기간 동안의 데이터베이스에서 발생하는 변화의 양을 예상해 볼 수 있습니다. 예측해 보건대, HOT Update는 일반 Update보다 더 적은 Write 작업을 하므로 WAL 또한 적게 생성할 것입니다.
실제 HOT Update의 실행 비율과 WAL 발생량 수치를 비교해 보겠습니다.
pg_current_wal_lsn(), pg_wal_lsn_diff(lsn1 pg_lsn, lsn2 pg_lsn)

결과를 보면 HOT Update 수행 비율이 낮은 Fillfactor의 경우 서로 다른 설정 중에서 가장 많은 양의 WAL을 생성하였으며, 테스트를 통해 HOT Update 실행 비율이 높아질수록 WAL 발생량이 감소하는 것을 직접 확인하였습니다.
마치며
이번 글에서는 Fillfactor값 조정을 통해 HOT Update가 동작하는 경우의 Update 성능, Dead Tuple의 수, Relation(Table/Index)의 크기 및 Write-Ahead Log (WAL) 발생량 등을 확인해 보았습니다. 테스트 결과는 다음과 같습니다.
- Fillfactor가 작을수록 HOT Update 발생 가능성은 높습니다.
Fillfactor가 작을수록 페이지 내 업데이트를 위한 공간이 많이 남아있으므로 변경 이전의 Tuple이 동일 페이지에 저장될 가능성이 높기 때문입니다. - Fillfactor가 작을수록 Dead Tuple 수는 줄어듭니다.
Fillfactor값이 작을수록 Single-page Vacuuming을 더 자주 수행하도록 유도하며, 그 과정에서 Dead Tuple들이 정리되기 때문입니다. - Fillfactor가 작을수록 초기 테이블 크기는 부풀려져 측정될 수 있습니다.
하지만 Update 수행이 반복될 경우 빈 공간이 채워지며, 해당 Update가 HOT Update로 처리될 확률이 높아, 결과적으로 공간 재사용 측면에서는 장점이 됩니다. - 테이블의 Fillfactor값과 상관없이 초기 인덱스 사이즈는 동일합니다.
하지만 Update 수행이 반복될 경우 Fillfactor가 작은 테이블에서는 HOT Update의 발생 빈도가 높을 것이며, HOT Update 동작은 추가적인 인덱스 엔트리를 생성하지 않기 때문에 인덱스 사이즈 측면에서도 장점이 있습니다. - HOT Update는 WAL 발생량에도 영향을 미칩니다.
Hot Update 수행 비율이 높을수록 일반적인 Update보다 적은 Write 작업이 필요하기 때문에 실제로 WAL발생량이 줄어드는 것을 알 수 있습니다.


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PostgreSQL New Feature - 16 Release (1) (2) | 2023.11.30 |
|---|---|
| DB 인사이드 | PostgreSQL Extension - PG_STAT_MONITOR (0) | 2023.09.21 |
| DB 인사이드 | PostgreSQL Replication - Slot (2) | 2023.07.26 |
| DB 인사이드 | PostgreSQL Replication - Parameter (6) | 2023.07.26 |
| DB 인사이드 | PostgreSQL Replication - 설정 확인 (0) | 2023.06.29 |




댓글