

안녕하세요. 네 번째 이.빅.스 입니다.
HDFS, Amazon S3, Google Cloud Storage 등 다양한 스토리지가 발전하면서 정형 데이터는 물론 비정형 데이터까지 대량으로 수용할 수 있게 되었고, 많은 기업들이 이런 스토리지들을 활용하여 방대한 양의 데이터를 수집하고 데이터 레이크를 만들고 있습니다.
이번 달에는 이러한 대용량 데이터 레이크를 쿼리할 수 있는 쿼리 엔진인 Trino를 소개합니다.

Trino는 하나 이상의 다양한 데이터 소스에 분산된 대규모 데이터 세트를 효율적으로 쿼리하도록 설계된 오픈 소스의 분산 SQL 쿼리 엔진입니다. Hive나 Pig처럼 MapReduce 작업의 파이프라인을 사용해 HDFS를 쿼리하는 도구의 대안으로 설계되었으나, 점차 확장되어 관계형 데이터베이스나 Cassandra와 같은 여러 데이터 소스를 다룰 수 있습니다. 표준 데이터베이스 기능을 제공하고 SQL을 다루기는 하지만, 데이터베이스는 아니기 때문에 MySQL, PostgreSQL, Oracle을 대체하지는 않습니다. HDFS를 비롯하여 클라우드 기반의 데이터 스토리지 등 다양한 스토리지 시스템에 상주하는 ORC 또는 Parquet과 같은 개방형 컬럼 지향 데이터 파일 형식을 포함하는 데이터 레이크를 쿼리할 수 있습니다.
Trino는 분산 SQL 쿼리 엔진(Presto)을 만든 초기 멤버들이 페이스북에서 나와 만든 PrestoSQL 프로젝트가 Trino로 Rebranding된 제품입니다. Presto는 페이스북이 최초로 개발하여 오픈 소스로 공개한 대화식 데이터 쿼리 서비스로, 빠른 속도의 쿼리 결과를 위해 엔진 레벨에서 분산 컴퓨팅 기법이 사용됩니다. Presto는 시간이 지나면서 PrestoSQL로 성장했고 PrestoSQL은 대용량 데이터를 향상된 효율성으로 빠르게 접근, 조회, 분석할 수 있는 솔루션이지만 점점 더 다양하고 방대한 양의 데이터를 수집하고 분석해야 할 필요성이 커지면서 기업들은 PrestoSQL보다 훨씬 더 강력한 것이 필요하다고 생각했습니다. 이에 따라 2020년 PrestoSQL은 더 강력한 솔루션인 Trino로 전환했습니다.

Trino는 원래 페이스북에서 사용하고자 설계되었지만 확장성과 유연성이 뛰어나 빅데이터 산업 전반에 적합한 SQL 쿼리 엔진으로 발전하였습니다. 특히 컴퓨팅과 스토리지가 분리되어 있기 때문에 클라우드 환경에서 운영하는데 매우 편리하며, 커넥터를 사용해 기존 데이터베이스, 비관계형 데이터베이스 등 다양한 데이터 소스에서 데이터를 쿼리할 때 높은 수준의 다양성과 편의성을 제공합니다. 또한 JSON, ARRAY, MAP과 같은 표준 데이터 및 반구조화된 데이터 유형들을 관리하고 표준 ANSI SQL을 지원하며, 사용자가 JSON이나 MAP 변환, 구문 분석과 같이 복잡한 변환을 실행할 수 있습니다.
Trino는 대규모 병렬 처리(MPP) 데이터베이스와 유사한 아키텍처를 활용하는 분산 시스템으로, 동일한 쿼리로 여러 서버 클러스터에 걸쳐 여러 컴퓨터에서 다양한 파일 유형에 액세스하여 데이터 소스를 쿼리할 수 있습니다. 단일 쿼리문으로 여러 데이터베이스를 쿼리할 수 있는 고유한 기능을 가지고 있습니다. 또한 불필요한 I/O 오버헤드를 피하기 위해 모든 처리는 메모리 내에서 이루어지며 단계 간에 네트워크를 통해 파이프라인이 구축됩니다. Trino의 동작 원리를 살펴보면, 다른 빅데이터 엔진과 유사하게 Coordinator와 Worker라는 2가지 타입의 서버가 있습니다. Coordinator는 쿼리 구문을 분석하고 실행할 쿼리를 계획하며, Worker 노드들을 관리합니다. 또한 Worker들로부터 받은 결과들을 최종적으로 클라이언트에게 리턴해주는 역할을 합니다. Worker는 실제 작업을 실행하고 데이터를 처리하는 역할을 담당합니다. Coordinator와 Worker는 REST API를 사용하여 통신하며, 기본 구성은 Coordinator 1대에 Worker는 1대 이상을 설치합니다.
Trino는 아래와 같이 클러스터를 모니터링하고 쿼리를 관리하기 위한 웹 기반 사용자 인터페이스를 제공합니다. 해당 UI를 통해 고유 쿼리 ID, 쿼리문, 쿼리 상태, 완료율 등을 확인할 수 있습니다.
현재 실행 중인 쿼리는 페이지 상단에 있으며, 가장 최근에 완료되거나 실패한 쿼리 내역도 하단에서 확인 가능합니다. 고유 쿼리 ID를 클릭하여 쿼리 세부 정보의 확인이 가능하며, 세부 내역에서 실행 중인 쿼리를 종료할 수 있고, 쿼리에 대한 통계를 이용하여 쿼리에 소요되는 시간을 분석할 수도 있습니다.




Trino는 대용량 데이터의 빠른 쿼리 속도를 활용하여 페타바이트 규모 이상의 데이터를 ETL할 때도 적합합니다.
Trino로 ETL을 하는 이유
- 표준 SQL 문을 활용하여 단순하게 ETL을 할 수 있다
- Trino는 메모리에서 모든 처리를 수행하기 때문에 속도면에서 빠르다.
- Trino의 최대 장점인 다양한 데이터 소스에서 읽을 수 있다.
- ORC에 최적화되어 있다.
- 사용자 정의 함수 기능을 이용하여 워크로드를 쉽게 분산할 수 있다.
- 처리량이나 인프라 환경에 따라 Trino의 속성값을 튜닝하면서 더욱 효율적으로 Trino를 사용할 수 있다.
데이터의 결과를 최대한 빠르게 분석하여 결과를 도출해야 하는 시대에 맞게 많은 기업들은 데이터 레이크를 활용하고자 합니다. 다양한 데이터 소스에 쉽게 연결할 수 있고, 분산 환경의 빠른 쿼리 처리 속도, 아키텍처의 확장성, Trino 속성을 튜닝하여 관리할 수 있다는 점을 활용하여 Facebook, Amazon, Netflix를 포함한 일부 대기업들은 Trino를 사용해 데이터 수집과 분석을 하고 있습니다. 실제로 S사 PoC에서 Trino와 C사 제품의 쿼리 속도를 비교해 봤을 때, Trino가 훨씬 빠른 처리 속도를 보이는 것을 확인했습니다. 아울러 Trino의 오픈소스 릴리즈 활동이 매우 활발한데다, 다양한 DB에 대한 지원과 편의성이 빠르게 늘어나며 최적화되고 있기 때문에 앞으로 더 많은 빅데이터 회사에서 Trino를 사용할 것으로 보입니다.
이런 Trino의 장점으로, 곧 출시될 EBIGs 2.0의 에코시스템을 업그레이드하면서 아키텍처에 Trino가 추가될 예정입니다.
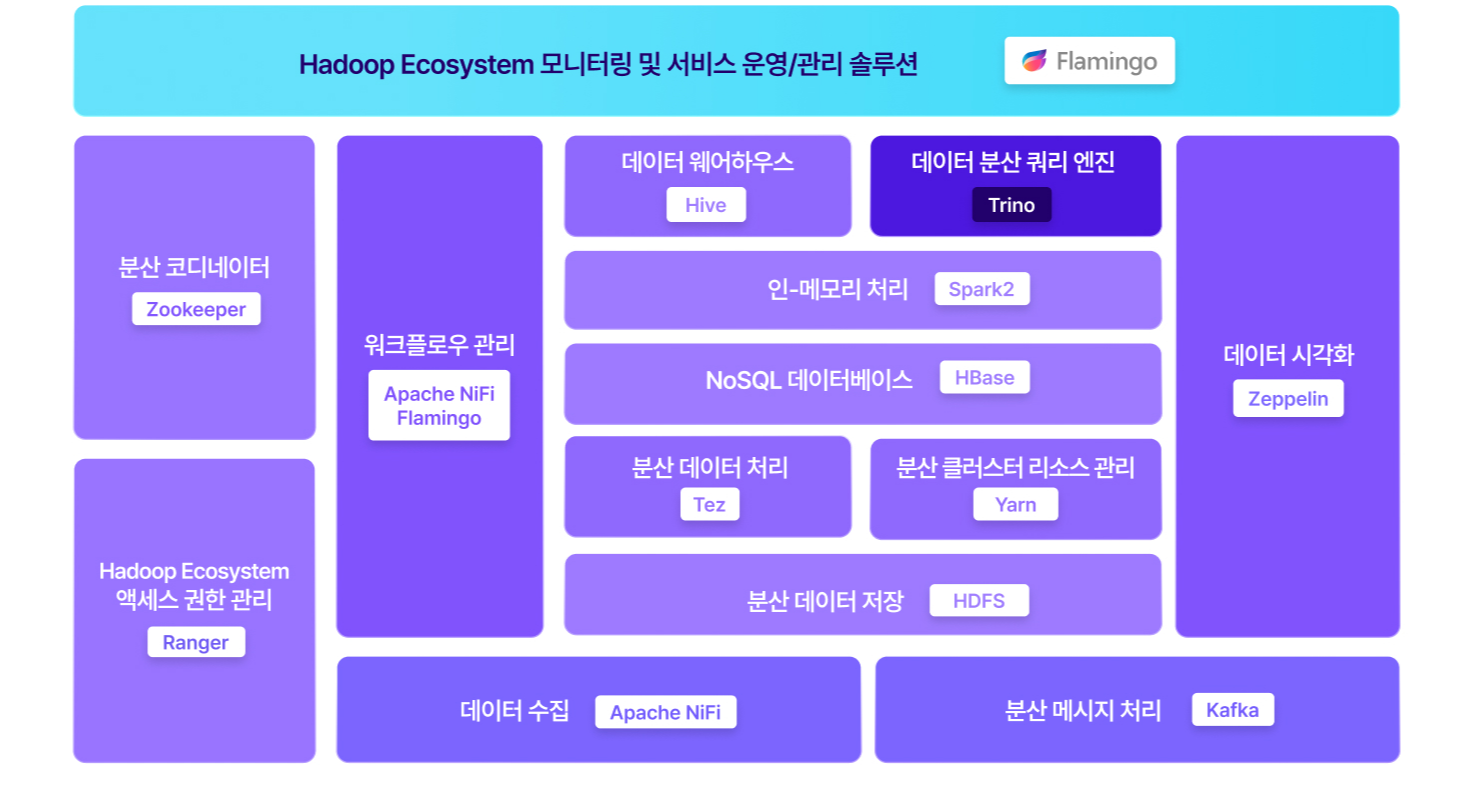
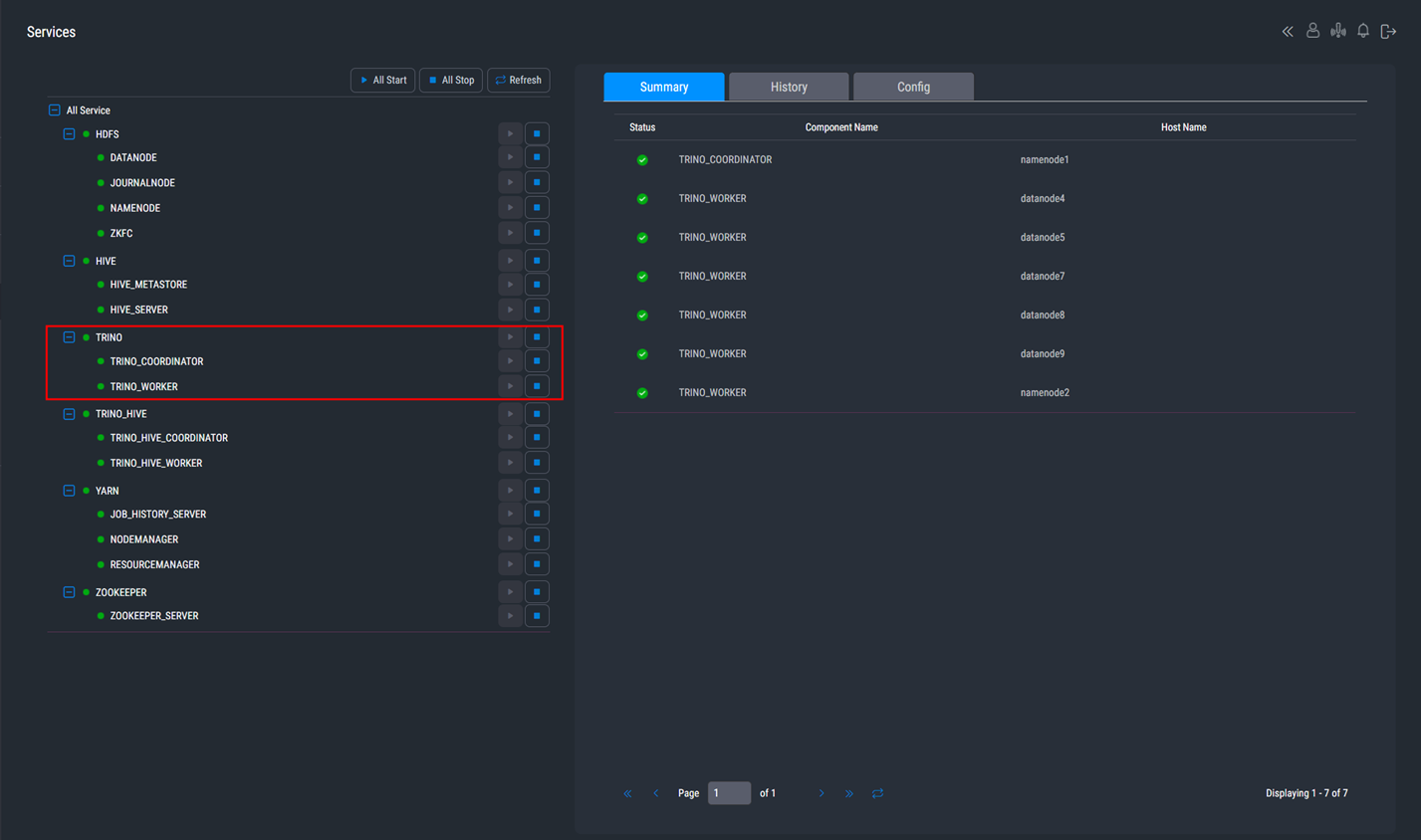
EBIGs에서 제공하는 모니터링 서비스인 Flamingo를 통해 Trino의 상태 확인이 가능합니다.
웹 UI를 통해 간편하게 Config를 수정하면 모든 서버에 일괄 반영되고, 서버 재기동도 가능하게 서비스될 예정입니다.

로고도 귀엽고 다양한 장점이 많은 쿼리 엔진 'Trino'와 새롭게 업그레이드 되는 EBIGs 2.0도 많은 관심 부탁드려요~
글 | 빅데이터기술연구팀 윤여원

'엑셈 경쟁력 > 이만큼 재미있는 빅데이터 스토리' 카테고리의 다른 글
| 이.빅.스. | Flamingo의 오픈소스 (1) | 2023.08.31 |
|---|---|
| 이.빅.스 | 빅데이터 가치를 위한 데이터 시각화 (0) | 2023.07.25 |
| 이.빅.스 | 실시간 데이터는 어떻게 활용할 수 있을까? (0) | 2023.03.30 |
| 이.빅.스 | 빅데이터는 왜 Hadoop에 저장해야 하는가? (0) | 2023.01.19 |
| 이.빅.스 l 이만큼 재미있는 빅데이터 스토리, 시작! (0) | 2022.10.26 |




댓글