두 개 이상의 트랜잭션에서 동일한 Row를 동시에 수정하는 것을 막기 위해서는 Lock을 통한 관리가 필요합니다. Relation의 하나의 레코드를 Row라 부르며, 물리적으로는 Tuple이라고 합니다. 그렇기 때문에 사용자가 생각하는 Row-level Lock은 실제로는 Tuple을 대상으로 동작한다고 볼 수 있습니다.
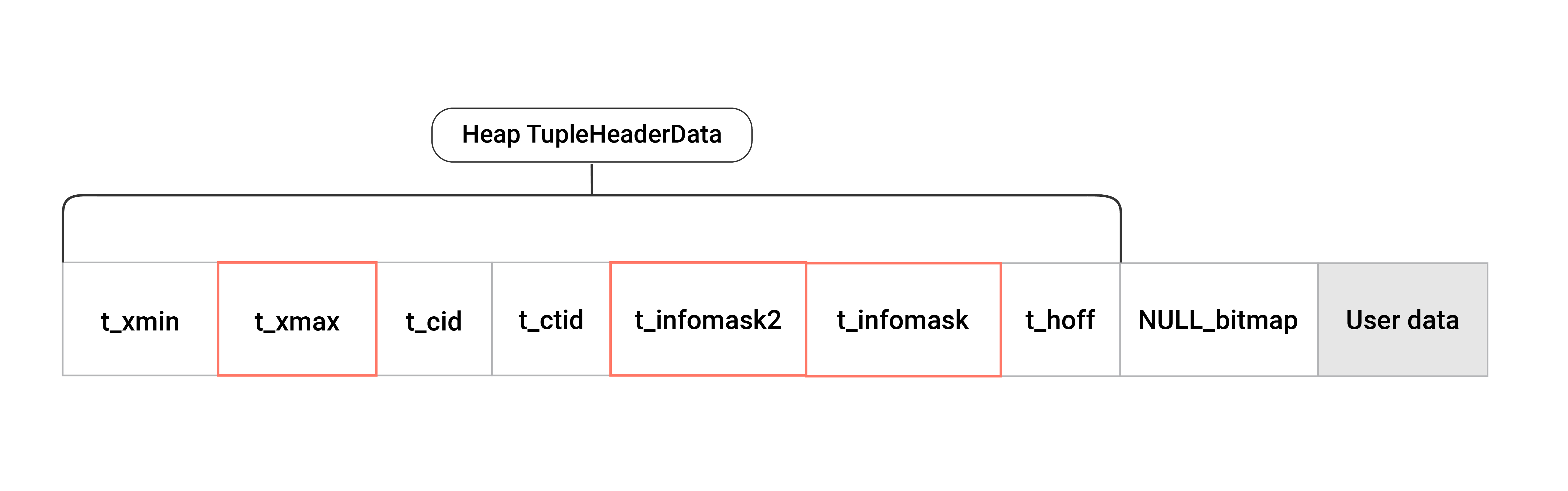
📢Tuple은 PostgreSQL의 MVCC 메커니즘에서 중요하게 활용되는 개념으로, 트랜잭션에 의해 변경된 Row를 여러 버전으로 관리하여 MVCC를 구현합니다. 이 때 각각의 버전이 Tuple이며, 다른 말로 Row Version이라고 합니다. Tuple에는 Header와 Data 영역이 있으며, Header는 다음과 같은 필드로 구성되어 있습니다.
xmin, xmax - 트랜잭션 ID 표시, 이는 동일한 Row를 가리키는 다른 버전과 해당 버전을 구별
cid - 현재 트랜잭션 내에서 이 Command가 실행되기 전에 실행된 SQL Command의 수
ctid - 같은 Row의 다음 업데이트 버전에 해당하는 Tuple을 가리키는 포인터
infomask - 버전 속성을 정의하는 정보를 나타내는 비트(Hint bit)
hoff - Tuple Header의 사이즈
null bitmap - NULL 값을 포함할 수 있는 열을 표시하는 비트 배열
Relation과 달리 Row는 한번에 대량의 변경 요청이 가능합니다. 이 경우, 실질적으로 해당 Row에 대응하는 Tuple에 대한 Lock 설정 이 필요한데, 이를 모두 공유 메모리에 저장하여 관리하는 것은 불가능합니다. 이를 해결하기 위해 PostgreSQL에서는 Two-level의 메커니즘을 사용합니다.
특징 1 : Two-level 메커니즘
Row-level Lock의 중요한 특징 중 하나로 Two-level 메커니즘은 다음과 같이 구현됩니다.
[Level 1] Lock Information Write : Tuple Header에 Lock 정보를 기록합니다. 이 메커니즘을 사용하면 적은 비용으로 많은 수의 Tuple에 대한 Lock을 설정할 수 있으므로, 동시에 많은 수의 Row에 대한 요청을 처리할 수 있습니다.
[Level 2] Wait Queue Manage : Tuple에 대한 HWLock(Heavyweight Lock)을 획득 및 해제하는 과정이 추가되며 Lock Manager를 사용합니다. 이 메커니즘은 두 개 이상의 트랜잭션이 동시에 동일한 Row에 수정 요청을 하는 경우, 해당 Lock에 대한 Wait Queue를 구현하여 해당 Tuple의 작업 순서를 관리할 수 있습니다.
모든 상황에서 Row-level Lock에 대해 HWLock을 사용하면, 서버의 공유 메모리 공간을 차지할 뿐만 아니라 Lock 대상이 많아지면 관리의 한계가 발생할 수 있습니다. 그러한 이유로 PostgreSQL에서는 현재 Row를 수정하고 있는 트랜잭션이 있다면, 그 정보를 Tuple에 기록하는 방식을 사용하여 Row-level Lock을 구현합니다. 그리고 필요한 경우에 대해서만, 추가적으로 Tuple에 대한 HWLock을 사용합니다.
[Level 1] Lock Information Write
위에서 설명한 바와 같이 트랜잭션이 현재 Row를 수정하는 중이라는 상태 정보를 Row에 대응하는 Tuple의 Header에 기록하는 방식입니다. Row를 수정하고자 하는 트랜잭션은 해당 Row에 작업 중인 다른 트랜잭션이 있는지 Tuple Header에 기록된 정보를 확인하여 작업 가능 여부를 알 수 있습니다.
이 메커니즘을 통해 Row-level Lock을 실재하는 Lock Object가 아닌 Tuple의 속성으로 관리하기 때문에 메모리를 추가로 사용하지 않는다는 장점이 있습니다.
📢 Tuple이 PostgreSQL의 Shared Buffer 내 Data Page의 Data 영역에 위치하고 있으므로, Tuple Header에 Lock 정보를 기록한다는 것은 Buffer 내 Data Page를 변경하고자 함을 의미합니다. 따라서 Buffer 관련 작업에 필요한 Lock을 획득하는 과정이 추가될 수 있음을 예상할 수 있습니다.
Row-level Lock 관련하여 Tuple Header에 정보를 기록하는 과정에 대해서 알아보겠습니다.
Tuple Header에는 Lock 정보를 포함하여 다양한 상태 정보를 저장하고 있습니다. 그중에서 Lock에 대한 정보와 연관되는 영역은 xmax, infomask 그리고 infomask2입니다. xmax에는 Row에 대해 작업 중인 트랜잭션의 ID를 기록하고 infomask, infomask2에는 Tuple의 상태 정보를 Bit로 저장합니다. 이 내용을 바탕으로 트랜잭션의 Commit/Rollback 여부, Row-level Lock, Update 처리 방식 등 다양한 정보를 알 수 있습니다.
📢 Tuple의 상태 정보를 Bit로 표시한 infomask, infomask2를 앞으로 infomask bit로 통칭하겠습니다.
트랜잭션이 Row를 수정하려고 하면, 먼저 해당 Row에 대응하는 Tuple Header의 xmax 값을 확인합니다. xmax 값이 NULL이라면, 현재 해당 Tuple에 작업 중인 트랜잭션은 없다고 판단하여 바로 작업이 가능합니다. 하지만 xmax에 트랜잭션 ID가 기록되어 있다면, 추가로 infomask bit를 확인하여 트랜잭션의 상태 및 Row-level Lock 설정 여부를 확인해야 합니다. 결과에 따라 xmax에 기록된 트랜잭션이 완료될 때까지 기다려야 합니다.
이 메커니즘에서는 작업 중인 트랜잭션 종료 후, 대기 중인 모든 트랜잭션의 대기가 해제됩니다. 만약 대기 중인 트랜잭션이 다수라면, 다음으로 작업할 트랜잭션을 정하기 위해 경쟁이 발생하게 되고, 이 과정에서 무기한 대기하는 트랜잭션이 생길 수 있습니다. 이러한 현상을 막기 위해서 Level 1 메커니즘보다 더 강한 Lock 메커니즘이 필요하게 됩니다.
[Level 2] Wait Queue Manage
위에서 설명한 이유로, Level 1 메커니즘을 통해 Row-level Lock 상태를 확인하여 트랜잭션의 대기 여부는 결정할 수 있지만, 대기 중인 트랜잭션 중에서 다음으로 작업하게 할 트랜잭션을 선정할 수는 없기 때문에 더 강한 Lock 메커니즘인 Level 2 메커니즘이 필요합니다.
Level 2 메커니즘은 Lock Manager를 사용하여 Wait Queue를 구현함으로써 Row-level Lock을 대기하는 트랜잭션들의 작업 순서를 제공합니다. Queue를 구현하기 위해서는 HWLock이 필요하므로 Tuple에 대한 HWLock을 획득 및 해제하는 동작이 추가됩니다.
📢 트랜잭션이 Row를 수정하려고 할 때, 동작 과정은 다음과 같습니다.
먼저 수정하고자 하는 Row에 대응하는 Tuple Header의 xmax와 infomask bit를 확인합니다. 다른 트랜잭션에 의해 수정 중인 Tuple이라면 Tuple에 대한 HWLock을 요청합니다.
HWLock을 획득에 성공했다면, 현재 Tuple을 수정 중인 트랜잭션의 종료 시점을 추적하기 위하여 해당 트랜잭션의 ID에 대하여 추가로 Lock을 요청합니다. 반면, 이미 다른 트랜잭션이 해당 HWLock을 가지고 있다면, HWLock 획득에 실패하며 Wait Queue에서 HWLock 획득을 대기합니다.
먼저 작업 중이었던 트랜잭션이 종료되면, 첫 번째로 대기 중이었던 트랜잭션이 Tuple을 수정할 수 있게 됩니다. Tuple Header의 xmax에 트랜잭션 ID를 기록하고 요청대로 infomask bit를 설정합니다.
획득했던 Tuple에 대한 HWLock을 해제합니다.
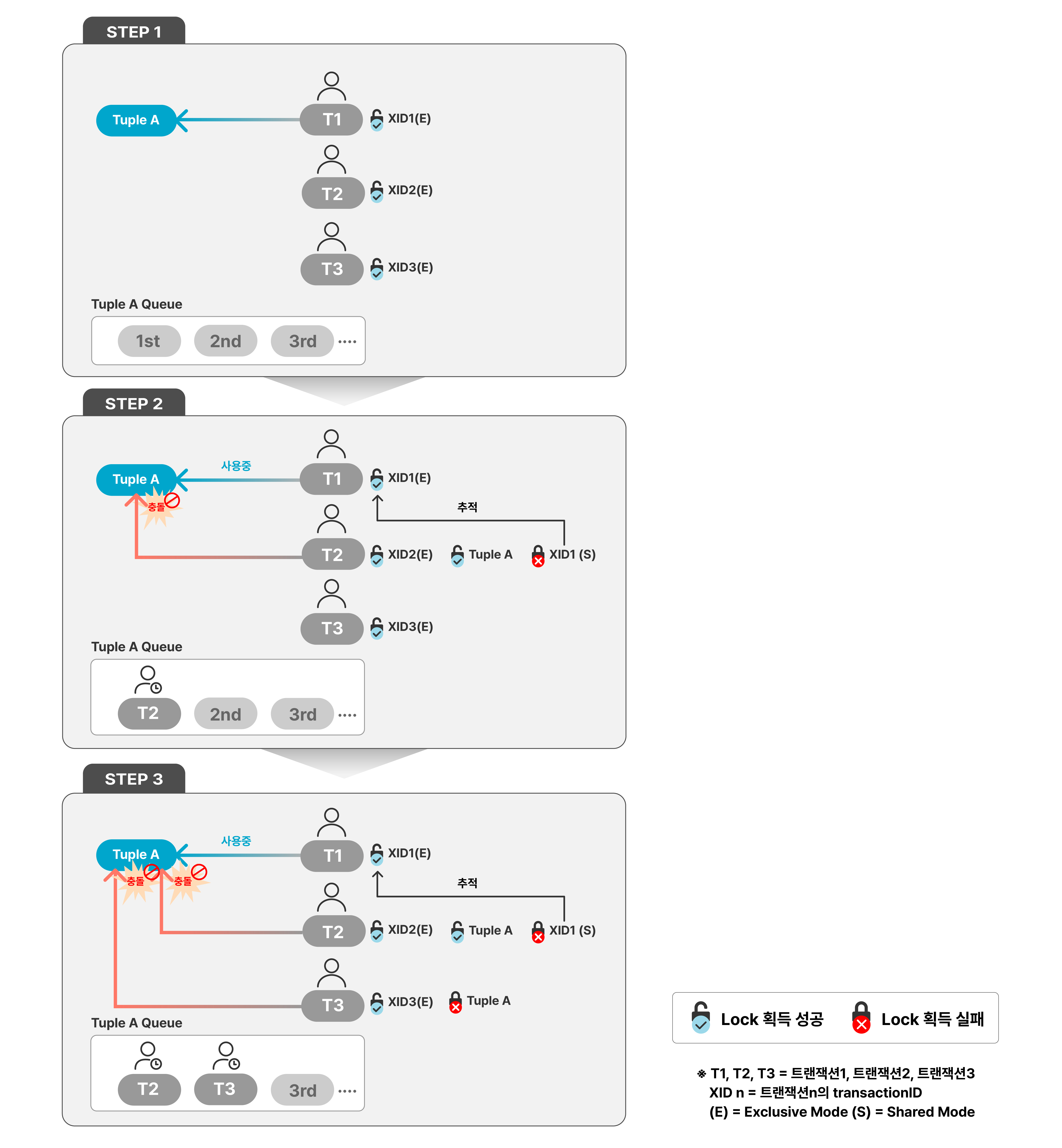
이번에는 Row-level Lock 충돌이 발생했을 때, Wait Queue를 구현하는 과정을 그림을 통해 자세히 살펴보겠습니다.
세 개의 트랜잭션(T1, T2, T3)이 순차적으로 같은 Row(Tuple A)를 수정하려고 하는 상황입니다.
세 트랜잭션은 모두 호환되지 않는 모드, ‘ExclusiveLock’을 요청하였다고 가정합니다.
T1, T2, T3 모두 자기 자신의 트랜잭션 ID에 대하여 Lock을 ‘Exclusive’ 모드로 획득한 상태입니다.
가장 먼저 T1이 Tuple A를 수정하려고 접근합니다. Tuple A의 Header에서 xmax와 infomask bit를 확인합니다. Tuple A는 다른 트랜잭션에 의해 사용중이지 않으므로 Tuple A Header에 T1의 트랜잭션 ID를 xmax에 기록하고, T1의 요청에 따라 Lock 정보를 포함한 상태 정보를 infomask bit에 설정합니다.
이후, T2도 Tuple A를 수정하려고 하지만, 먼저 Tuple A는 T1에 의해 수정 중인 상태로 접근이 차단됩니다. Tuple A 작업을 하기 위해, Tuple A에 대해 Lock을 요청하고 Wait Queue에서 대기합니다. (이때, T2는 Tuple A에 대한 Lock 획득에 성공합니다. T2는 첫 번째 대기 트랜잭션을 의미하며, T1 종료 후 최우선 순위로 Tuple A를 수정할 수 있습니다.) 그리고 T2는 먼저 작업 중인 T1의 트랜잭션 종료 시점을 추적하기 위해서 T1의 트랜잭션 ID에 대한 ‘ShareLock’을 요청하지만, T1의 트랜잭션 ID에 대해 T1이 ‘ExclusiveLock’을 가지고 있으므로 획득에 실패할 수 밖에 없기 때문에 Sleep 상태로 대기합니다.
T3도 Tuple A를 수정하고자 접근합니다. 하지만 Tuple A가 다른 트랜잭션 T1이 현재 사용 중이기 때문에, 대기를 위해 T2와 마찬가지로 Tuple A에 대한 Lock을 요청합니다. 그러나 이미 T2가 Tuple A에 대하여 Lock을 획득한 상태이므로 T3는 획득엔 실패하고 Wait Queue에서 자신의 순서까지 기다립니다.
T1 트랜잭션 종료 후, T2가 Tuple A에 접근하여 수정할 수 있게 되어 T2는 Tuple A에 대한 HWLock을 해제합니다. 따라서 Wait Queue에서 대기 중이던 T3가 Tuple HWLock을 획득하고 첫 번째 대기자가 되어 T2 트랜잭션 종료 시점을 추적합니다.
📢 Level 2 메커니즘에서 사용하는 Tuple에 대한 HWLock은 pg_locks에서 조회 가능합니다. (locktype=`tuple`)
이어서 Row-level Lock에서 사용하는 Lock Mode의 종류를 소개하고, 각 모드 별로 어떻게 동작하는지 알아보겠습니다.
특징 2 : 4가지 Lock Mode
Row-level Lock의 Level 1 메커니즘에서 사용하는 Lock Mode는 FOR KEY SHARE, FOR SHARE, FOR NO KEY UPDATE, FOR UPDATE 4가지 입니다. 각 모드는 Tuple Header의 infomask bit에 서로 다르게 기록됩니다.
Lock Mode는 SQL Command에 따라 자동으로 모드가 선택되기도 하지만 명시적으로 지정할 수도 있습니다. 자동으로 선택되는 경우, 선택 가능한 모드 중에서 가장 약한 모드, 즉 상호 호환성이 좋은 모드가 선택됩니다.
아래 표는 모드 간 호환성을 표시하고 있습니다. (‘X’는 모드 간 호환이 되지 않는다는 의미로, 충돌이 발생합니다.)
FOR KEY SHARE
FOR SHARE
FOR NO KEY UPDATE
FOR UPDATE
FOR KEY SHARE
X
FOR SHARE
X
X
FOR NO KEY UPDATE
X
X
X
FOR UPDATE
X
X
X
X
Exclusive Mode
4가지 모드 중에서 ‘FOR UPDATE’와 ‘FOR NO KEY UPDATE’ 모드는 다른 모드와 호환될 수 없는 특징을 가지는 Exclusive Lock의 성격을 가집니다.
FOR UPDATE - 모든 종류의 Row Update 및 Delete 작업이 선택할 수 있는 모드로, 다른 모드와 호환되지 않습니다.
FOR NO KEY UPDATE - Unique Index에 포함되지 않는 영역에 대한 Row Update 및 Delete 작업에 한해서 선택할 수 있는 모드입니다. ‘FOR UPDATE’ 모드와 다르게 ‘FOR KEY SHARE’ 모드와 호환될 수 있습니다.
Lock Mode는 선택 가능한 모드 중 가장 약한 모드를 선택한다는 원칙에 따라, Key가 아닌 영역에 대한 Update/Delete가 수행될 때는 ‘FOR NO KEY UPDATE’ 모드가 대부분 선택됩니다.
다음과 같이 예시를 통해 위 두 가지 Lock Mode에 대해서 Row-level Lock이 어떻게 처리되는지 살펴보겠습니다.
Tuple Header에 기록된 Row-level Lock 정보를 쉽게 확인하도록 pageinspectExtension을 활용하여 Function을 생성합니다. 그리고 테스트를 위해 row_test테이블을 생성하고 데이터를 입력합니다.
-- pageinspection Extension
CREATE EXTENSION pageinspect;
-- Header 정보 변환하는 Function 생성
CREATE FUNCTION heap_page(relname text, pageno integer)
RETURNS TABLE(
ctid tid
, xmin text
, xmax text
, LOCK_ONLY text
, IS_MULTI text
, HOT_UPDATED text
, KEYS_UPDATED text
, KEYSHR_LOCK text
, SHR_LOCK text
, t_ctid tid
)
AS $$
SELECT (pageno,lp)::text::tid as ctid,
t_xmin || CASE
WHEN (t_infomask & 256) > 0 THEN ' (c)'
WHEN (t_infomask & 512) > 0 THEN ' (a)'
ELSE ''
END AS xmin,
t_xmax || CASE
WHEN (t_infomask & 1024) > 0 THEN ' (c)'
WHEN (t_infomask & 2048) > 0 THEN ' (a)'
ELSE ''
END AS xmax,
CASE WHEN t_infomask & 128 = 128 THEN 'T' end as LOCK_ONLY,
CASE WHEN t_infomask & 4096 = 4096 THEN 'T' end as IS_MULTI,
CASE WHEN t_infomask2 & 16384 = 16384 THEN 'T' end as HOT_UPDATED,
CASE WHEN t_infomask2 & 8192 = 8192 THEN 'T' end as KEYS_UPDATED,
CASE WHEN t_infomask & 16 = 16 THEN 'T' end as KEYSHR_LOCK,
CASE WHEN t_infomask & 16+64 = 16+64 THEN 'T' end as SHR_LOCK,
t_ctid
FROM heap_page_items(get_raw_page(relname,pageno))
ORDER BY lp;
$$ LANGUAGE sql;
-- 테스트 테이블 생성 및 데이터 입력
CREATE TABLE row_test(
c1 integer PRIMARY KEY,
c2 text,
c3 numeric
);
INSERT INTO row_test values
(1, 'row1', 100.00), (2, 'row2', 200.00), (3, 'row3', 300.00);
c1|c2 |c3 |
--+----+------+
1|row1|100.00| -- ctid(0,1)
2|row2|200.00| -- ctid(0,2)
3|row3|300.00| -- ctid(0,3)
다음과 같이 하나의 트랜잭션에서 row_test 테이블의 Primary Key인 c1 컬럼에 대한 Update Command와 Primary Key가 아닌 c3 컬럼에 대한 Update Command를 수행합니다.
BEGIN;
-- UPDATE(1) - FOR UPDATE
update row_test set c1 = 20 where c1 = 1;
-- UPDATE(2) - FOR NO KEY UPDATE
update row_test set c3 = c3 + 100.00 where c1 = 2;
지금까지 내용을 모두 이해했다면, Primary Key를 수정하고자 하는 UPDATE(1)은 ‘FOR UPDATE’ 모드, Key가 아닌 영역에 대한 Update 요청을 한 UPDATE(2)는 ‘FOR NO KEY UPDATE’ 모드를 선택할 것으로 예상할 수 있습니다. 앞서 생성한 heap_page 함수를 통해 Tuple Header에 Row-level Lock이 기록되었는지 결과를 확인해 보겠습니다.
-- heap_page : Tuple의 상태 확인 (xmax, infomask bit를 통한 Row-level Lock 속성)
SELECT * FROM heap_page('row_test', 0) ;
①UPDATE(1)의 대상 ctid(0,1)에 해당하는 Tuple에 기록된 내용은 key_updated가 T로, ‘FOR UPDATE’ 모드임을 나타냅니다. 그리고 ②UPDATE(2)에 의해서 수정되는 ctid(0,2)인 Tuple은 keys_updated, keyshr_lock, shr_lock 모두 NULL인 결과를 바탕으로 FOR UPDATE, FOR KEY SHARE, FOR SHARE이 아닌 ‘FOR NO KEY UPDATE’ 모드로 Row-level Lock을 기록하였다는 것을 확인할 수 있습니다.
📢 위 결과의 ctid 컬럼은 heap_page Function 생성 시 정의한 내용으로, `(0,2)`는 Page 번호가 0, Line Pointer가 1인 Tuple을 가리키는 값입니다. 그리고 hot_updated 항목이 `T`인 것은 Update가 HOT(Heap-Only Tuple) Update로 처리되었다는 것을 뜻합니다. [참고] PostgreSQL HOT - Update 동작 과정 https://blog.ex-em.com/1771
뿐만 아니라, Select For Command를 사용해서 명시적으로 ‘FOR UPDATE’와 ‘FOR NO KEY UPDATE’ 모드의 Row-level Lock을 사용할 수도 있습니다. 이전 예시의 Update와 다른 점은 Row를 변경하는 작업은 아니기 때문에 lock_only 항목이 T로 설정된다는 것입니다.
select * from row_test where c1 = 1 FOR UPDATE;
select * from row_test where c1 = 2 FOR NO KEY UPDATE;
-- heap_page : Tuple의 상태 확인
SELECT * FROM heap_page('row_test', 0) ;
Shared Mode
Select For Command를 사용하여 명시적으로 Row-level Lock을 다음과 같은 모드로 사용할 수 있습니다.
FOR SHARE - 모든 읽기 작업에서 선택할 수 있는 모드로, 다른 트랜잭션에 의한 모든 종류의 Tuple 수정을 제한합니다.
FOR KEY SHARE - 읽기 작업에서 선택될 수 있는 모드인 것은 ‘FOR SHARE’ 모드와 동일하지만, Key 속성에 해당하는 Tuple의 수정 및 제거 작업은 제한합니다. 즉, Key 변경 없이 Tuple을 수정하려고 하는 트랜잭션은 차단하지 않습니다. (내부에서 외래 키를 확인할 때 사용되는 모드이기도 합니다.)
📢 일반적인 Select Command는 Row-level Lock을 사용하지 않습니다.
다음은 Row-level Lock을 Shared Mode로 사용하는 예시입니다.
BEGIN;
-- SELECT(1) - SHARE
select * from row_test where c1 = 1 for share;
-- SELECT(2) - KEY SHARE
select * from row_test where c1 = 2 for key share;
Select For Command를 사용하여 명시적으로 Row-level Lock를 Shared Mode로 선택하게 합니다. SELECT(1)과 SELECT(2)는 모두 읽기 작업이지만, 명시적으로 작성한 구문이므로 서로 다른 모드가 선택됩니다. Tuple Header에는 어떻게 기록되었는지 heap_page를 사용하여 확인해 보겠습니다.
-- heap_page : Tuple의 상태 확인
SELECT * FROM heap_page('row_test', 0) ;
①두 Command에 의해 ctid(0,1)과 ctid(0,2)에 해당하는 Tuple의 lock_only와 keyshr_lock 값이 T로 설정 것을 볼 수 있습니다. 그리고 ②’FOR SHARE’ 모드로 Row-level Lock을 설정한 Tuple ctid(0,2)에는 shr_lock이 추가로 설정되었습니다.
Tuple HWLock
Row-level Lock의 두 가지 메커니즘 중 Level 2에 해당하는 Lock Queue Manage 경우에는 Queue 구현을 위해서 Tuple에 대한 HWLock을 획득하고 해제하는 과정이 추가된다는 것을 이해했다면, Tuple에 대한 HWLock을 획득 요청할 때 어떤 모드로 요청하는지 의문이 생길 수 있습니다.
## postgres/src/backend/access/heap/heapam.c
/*
* Each tuple lock mode has a corresponding heavyweight lock, and one or two
* corresponding MultiXactStatuses (one to merely lock tuples, another one to
* update them). This table (and the macros below) helps us determine the
* heavyweight lock mode and MultiXactStatus values to use for any particular
* tuple lock strength.
*
* Don't look at lockstatus/updstatus directly! Use get_mxact_status_for_lock
* instead.
*/
static const struct
{
LOCKMODE hwlock;
int lockstatus;
int updstatus;
}
tupleLockExtraInfo[MaxLockTupleMode + 1] =
{
{ /* LockTupleKeyShare */
AccessShareLock,
MultiXactStatusForKeyShare,
-1 /* KeyShare does not allow updating tuples */
},
{ /* LockTupleShare */
RowShareLock,
MultiXactStatusForShare,
-1 /* Share does not allow updating tuples */
},
{ /* LockTupleNoKeyExclusive */
ExclusiveLock,
MultiXactStatusForNoKeyUpdate,
MultiXactStatusNoKeyUpdate
},
{ /* LockTupleExclusive */
AccessExclusiveLock,
MultiXactStatusForUpdate,
MultiXactStatusUpdate
}
};
/* Get the LOCKMODE for a given MultiXactStatus */
#define LOCKMODE_from_mxstatus(status) \
(tupleLockExtraInfo[TUPLOCK_from_mxstatus((status))].hwlock)
/*
* Acquire heavyweight locks on tuples, using a LockTupleMode strength value.
* This is more readable than having every caller translate it to lock.h's
* LOCKMODE.
*/
#define LockTupleTuplock(rel, tup, mode) \
LockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
#define UnlockTupleTuplock(rel, tup, mode) \
UnlockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
#define ConditionalLockTupleTuplock(rel, tup, mode) \
ConditionalLockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
Tuple HWLock의 Lock Mode는 “설정하고자 하는” Row-level Lock의 Lock Mode에 따라 다음과 같이 결정됩니다.
Row-level Lock
Tuple HWLock
FOR KEY SHARE
AccessShareLock
FOR SHARE
RowShareLock
FOR NO KEY UPDATE
ExclusiveLock
FOR UPDATE
AccessExclusiveLock
Tuple HWLock의 모드는 Row-level Lock과 마찬가지로 AccessShare, RowShare, Exclusive, AccessExclusive 4가지 모드를 제공합니다.
실제 테스트를 통해 SQL Command에 따라 Row-level Lock과 Tuple HWLock이 어떤 Lock Mode를 사용하는지 확인해 보겠습니다.
T: Transaction
T1) Row-level Lock: FOR UPDATE
update tuple_test set c1 = 20 where c1 = 1;
T2) Row-level Lock: FOR UPDATE -> Tuple HWLock: AccessExclusiveLock
update tuple_test set c1 = 20 where c1 = 1;
T3) Row-level Lock: FOR NO KEY UPDATE -> Tuple HWLock: ExclusiveLock
update tuple_test set c3 = c3 + 100.00 where c1 = 1;
T4) Row-level Lock: FOR SHARE -> Tuple HWLock: RowShareLock
select * from tuple_test where c1 = 1 for share;
T5) Row-level Lock: FOR KEY SHARE -> Tuple HWLock: AccessShareLock
select * from tuple_test where c1 = 1 for key share;
각각의 작업은 개별 트랜잭션을 통해 서로 다른 Command를 수행하지만, 모두 동일 Row를 대상으로 합니다. 이에 선택되는 Row-level Lock Mode는 모두 상이합니다.
가장 먼저 Row에 수정 요청을 한 T1은 Tuple Header에 Row-level Lock 상태를 기록하는 Level 1 메커니즘 (Lock Information Write)을 따르며, 이는pgrowlocks결과를 통해 확인해 보겠습니다.
그 외 트랜잭션은 모두 Level 2 메커니즘(Wait Queue Manage)에 따라 Tuple HWLock을 요청한 후 자기 차례를 기다리므로pg_locks를 통해 Tuple LWLock을 확인해 보겠습니다.
pgrowlocks(’tuple_test’)pg_locks
📢 PostgreSQL에서는 Row-level Lock을 확인하기 위한 pgrowlocks Extension을 제공합니다. pgrowlocks를 사용하면 매개변수로 입력한 테이블의 Row-level Lock 정보를 확인할 수 있습니다.
①pgrowlocks를 조회 결과에서 modes가 {Update}인 것을 통해 첫 번째 트랜잭션인 T1은 ‘FOR UPDATE’ 모드로 Row-level Lock을 설정한 것을 알 수 있습니다. ‘FOR UPDATE’ 모드는 다른 모드와 상호 호환되지 않습니다.
이어서 T2가 T1과 같은 Row를 변경하려고 하지만 T1이 먼저 해당 Row에 대응하는 Tuple을 수정하고 있으므로 대기해야 합니다. ②pg_locks 조회 결과를 통해 T2는 Primary Key를 포함해서 변경 요청을 하였으므로 Row-level Lock은 ‘FOR UPDATE’ 모드를 선택, 그에 따라 Tuple에 대한 HWLock은 AccessExclusiveLock을 획득하였다는 것을 알 수 있습니다. (granted=true)
③key에 해당하지 않는 업데이트를 요청한 T3는 Row-level Lock을 ‘FOR NO KEY UPDATE’ 모드를 선택, 따라서 Tuple HWLock은 ExclusiveLock을 요청하였습니다. 이어서 ④Select For share Command를 수행한 T4는 Row-level Lock은 ‘FOR SHARE’ 모드로 요청, Tuple HWLock은 RowShareLock으로 획득 대기합니다. 마지막으로 ⑤T5는 Select Forkey share Command를 수행하였으므로 Row-level Lock은 ‘FOR KEY SHARE’ 모드이며, Tuple HWLock에 대해서는 AccessShareLock 모드로 요청하였습니다.
③~⑤ T3 ~ T5는 T2와 마찬가지로 T1과 같은 Row에 접근하고자 합니다. 동시에 작업할 수 없으므로 대기를 위해 해당 Tuple에 대한 HWLock을 요청하지만 T2가 이미 획득한 상황이므로 획득에는 실패합니다. (granted=false)
마무리
지금까지 PostgreSQL의 Row-level Lock에 대한 특징과 사용하는 Lock Mode, 그리고 세부적인 동작과정에 대해 살펴보았습니다.
쉽지 않은 내용이지만, 다시 한번 Row-level Lock의 주요 내용을 요약해 보면 다음과 같습니다.
Row-level Lock은 PostgreSQL 내부에서는 Tuple을 대상으로 동작한다.
Row-level Lock에 대하여 Two-level의 메커니즘, Lock information Write와 Wait Queue Manage를 사용한다.
Level 1 메커니즘은 Row-level Lock에 대한 정보를 Tuple Header의 xmax와 infomask bit(infomask, infomask2)에 기록한다.
Level 2 메커니즘은 Row-level Lock을 기록(수정) 하는 과정에서 Conflict 발생 시 추가적으로 필요하며, Lock Manager를 사용하여 Tuple에 대한 HWLock을 획득 및 해제하는 과정을 통해 Wait Queue를 구현한다.
Row-level Lock의 Lock Mode는 4가지가 있으며, 설정하고자 하는 Lock Mode에 따라 Tuple에 대한 HWLock의 Lock Mode가 결정된다.
다음 글에서는 트랜잭션이 Row를 수정하려고 할 때, Row-level Lock 관련하여 어떻게 동작하는지 테스트를 통해 확인해 보겠습니다. 그리고 Row-level Lock에 대한 경합 상황에서 Dead Lock이 발생하는 상황도 함께 살펴보겠습니다.












댓글