

📢 PWI(PostgreSQL Wait Interface) - LOCK
PostgreSQL의 Wait Event에 대하여 다루기 전에, 먼저 PostgreSQL에서 사용하는 Lock에 대한 전반적인 내용을 다룰 예정입니다.
PostgreSQL은 Relation과 같은 Object를 보호하는 Heavyweight Lock(HWLock), Relation의 구성 요소의 하나인 Row를 다루는 Row-level Lock, 그리고 일반적으로 공유 메모리의 데이터 구조에 접근할 때 사용하는 Lightweight Lock(LWLock) 등 다양한 유형의 Lock을 제공합니다.
앞으로 PWI - Locks에서는 PostgreSQL에서 사용하는 Lock의 종류와 특징, 동작 방식 등을 알아보고, 사용 예시를 통하여 Lock을 획득 및 해제하는 과정을 확인해 보도록 하겠습니다.
Predicate Lock
PostgreSQL에서는 Serializability를 보장하기 위하여 Predicate Lock을 사용합니다. 가장 엄격한 트랜잭션 격리 레벨인 Serializable Isolation Level에서 제공되며, 동시 트랜잭션 환경에서도 트랜잭션이 직렬로 실행되는 것처럼 동작하는 것을 보장합니다.
📢 Serializable Isolation Level은 Serializable Snapshot Isolation(SSI) 기술을 기반으로 동작하므로 First-Committer-Winner 원칙에 따라 트랜잭션을 제어합니다. 여러 트랜잭션이 같은 데이터를 사용하는 상황에선, 가장 먼저 Commit을 수행한 트랜잭션의 작업만 적용되고 나머지 트랜잭션의 작업은 Rollback 처리됩니다. 이 과정에서 serialization anomaly*를 초래할 수 있으므로 Read/Write Dependency 데이터 종속 관계를 추적 및 관리해야 하는데, 이때 Predicate Lock이 사용됩니다.
- serialization anomaly (ex. write-skew)
동시 트랜잭션 상황에서 해당 Row에 작업한 다른 트랜잭션의 결과로 인해 동일한 Row를 읽었지만 데이터가 불일치하는 현상입니다. 이는 동시에 Commit 된 트랜잭션이 각각 개별적으로 실행되었을 때와 결과가 달라지게 합니다.
Predicate Lock은 다른 일반적인 Lock처럼 작업을 제한하지는 않아 더 많은 동시성이 가능합니다. 동시 수행되는 트랜잭션 간의 데이터 종속 관계를 모니터링해서 RW 충돌을 식별하고, serialization anomaly이 의심되는 경우 트랜잭션을 중단합니다. (WR 충돌의 경우에는 일반 Lock을 사용하여 감지할 수 있기 때문에 Predicate Lock는 RW 충돌만 고려하면 됩니다.)
📢 다음은 읽기 및 쓰기 작업 중에 발생하는 세 가지 유형의 충돌입니다.
- WR 충돌 : Dirty Read, 다른 트랜잭션(Commit 이전)이 Write 한 데이터를 Read 할 때 발생함
- RW 충돌 : Unrepeatable Read, 트랜잭션이 이전에 Read 한 데이터를 Write 할 때, 다른 트랜잭션의 Write 작업으로 인해 해당 Commit 전/후 데이터 Read 결과가 달라짐 (같은 트랜잭션 내에서 동일한 쿼리에 대한 결과 값이 상이함)
- WW 충돌 : Lost Update, 다른 트랜잭션이 이미 Write 한 데이터를 Write 하여 작성된 데이터를 덮어쓰는 바람에 먼저 기록된 데이터가 사라짐
Predicate Lock은 관련 있는 Read-Write 트랜잭션이 모두 완료될 때까지 유지되어야 하기 때문에, 다른 일반적인 Lock과는 달리 트랜잭션을 종료한 이후에도 Lock이 해제되지 않습니다. 그리고 pg_locks를 조회하여 Predicate Lock에 대한 정보를 확인할 수 있습니다. 다른 Lock과 차이점이 있다면, 어떤 대상을 보호하려는 목적의 Lock이 아니기 때문에, predicate라는 locktype은 별도로 존재하지 않습니다. 대신 mode=SIReadLock으로 표시되는 모든 Lock을 Predicate Lock으로 지칭합니다.
특징 1 : 동작 범위
Predicate Lock의 동작 범위는 (Relation의) Tuple, Page 그리고 Relation 수준에서 동작하며, 실제로 Access 하는 데이터를 기반으로 설정됩니다. 따라서 동일한 테이블에 대한 Read 작업 시, 조회 조건이나 실행 계획에 따라 데이터 Access 범위가 달라진다면 Predicate Lock의 설정 범위도 달라질 수 있습니다.
또한 Relation에 Index가 존재 할 경우 아래와 같은 특징을 갖습니다.
- Predicate Lock을 지원하는 인덱스 : B-tree, Hash, GiST, GIN
- Predicate Lock을 지원하지 않는 인덱스를 사용한 경우, Index Scan 시 Index Page 일부가 아닌 전체 Index에 대하여 Lock이 설정됩니다.)
Sequential Scan vs Index Scan
다음과 같이 실행 계획이 Sequential Scan과 Index Scan으로 다른 경우, Predicate Lock이 어떻게 동작하는지 테스트를 통해 살펴보겠습니다.
- Sequential Scan
BEGIN ISOLATION LEVEL SERIALIZABLE;
EXPLAIN (analyze, costs off)
SELECT * FROM pred WHERE c1 > 100;
QUERY PLAN
-----------------------------------------------------------------
Seq Scan on pred (actual time=11.706..33.017 rows=9900 loops=1)
Filter: (c1 > 100)
Rows Removed by Filter: 100
Planning Time: 2.014 ms
Execution Time: 44.178 msc1 > 100로 조건절을 작성하여 pred 테이블에 Select Command를 수행한 후, 실행 계획을 확인하면 Seq Scan on pred 로, Sequential Scan을 수행하였음을 알 수 있습니다.

pg_locks 조회 결과, relation locktype으로 테이블 pred에 대하여 mode=SIReadLock이 표시되었습니다. 이를 통해 Predicate Lock이 Relation에 대하여 설정되었다는 것을 확인할 수 있습니다.
- Index Scan
BEGIN ISOLATION LEVEL SERIALIZABLE;
EXPLAIN (analyze, costs off)
SELECT * FROM pred WHERE c1 BETWEEN 1000 AND 1001;
QUERY PLAN
-------------------------------------------------------------------------------
Index Scan using pred_idx on pred (actual time=13.051..32.447 rows=2 loops=1)
Index Cond: ((c1 >= 1000) AND (c1 <= 1001))
Planning Time: 1.248 ms
Execution Time: 32.613 ms이번에는 Index Scan을 유도하기 위해 조건절을 c1 BETWEEN 1000 AND 1001로 변경하였고, Index Scan using pred_idx on pred를 통해 결과를 확인 가능합니다.

조회 결과 중, 인덱스(pred_idx)와 관련된 내용을 제외하면, 2개의 tuple locktype이 확인됩니다.
이는 읽고자 하는 테이블 pred에 대해서 Relation 수준의 Predicate Lock을 설정하는 것이 아닌, 특정 Row에 대해서만 Predicate Lock을 설정하였다는 것을 나타냅니다.
특징 2 : Lock Escalation
Predicate Lock은 빠른 Access를 위해 메모리에 저장되기 때문에, 이를 저장하기 위한 공간 할당 및 관리의 어려움 등의 문제로 항상 Tuple 수준의 Lock을 유지하는 것은 불가능합니다. 따라서 필요시 Lock Escalation과정을 거쳐 여러 개의 세분화된 Lock을 단일 Lock으로 병합하는데, 그 과정은 작은 범위의 Lock의 수가 일정 개수를 초과할 때 큰 범위(Tuple < Page < Relation)로 일괄 통합되는 방식이 사용됩니다. 이를 통해 관리하는 Lock의 수를 조절할 수 있습니다.
Lock Escalation은 다음과 같은 파라미터 설정에 따라 결정되며, 이는 postgresql.conf 에서 변경 가능합니다.
- max_pred_locks_per_page (Default= 2) : 하나의 Page 당 설정 가능한 Predicate Lock의 수입니다. 이 값보다 작으면 대상 Row에 대해서만 Predicate Lock이 설정되므로 locktype=
tuple에 해당하지만, 이 값보다 크면 Tuple이 저장된 Page에 대한 Predicate Lock으로 Escalation 됩니다. - max_pred_locks_per_relation (Defalut= -2): 하나의 Relation 당 설정 가능한 Predicate Lock의 수입니다. 이 값보다 큰 경우에는 Page가 아닌 Relation에 대한 Predicate Lock으로 Escalation 됩니다. 만약 이 값이 음수라면, max_pred_locks_per_transaction에 설정된 값을 max_pred_locks_per_relation의 절댓값으로 나눈 값을 의미합니다.
Lock Escalation 예시
BEGIN ISOLATION LEVEL SERIALIZABLE;
EXPLAIN (analyze, costs off)
SELECT * FROM pred WHERE c1 BETWEEN 1000 AND 1002;
QUERY PLAN
------------------------------------------------------------------------------
Index Scan using pred_idx on pred (actual time=0.113..14.079 rows=3 loops=1)
Index Cond: ((c1 >= 1000) AND (c1 <= 1002))
Planning Time: 0.581 ms
Execution Time: 14.229 ms위 예시에서는 c1 BETWEEN 1000 AND 1002와 같이 조건절을 작성하였으며, 3개의 Row를 Read 하는 Select Command입니다. 따라서 locktype이 tuple인 Predicate Lock을 3개 설정되었을 것으로 예상하지만, pg_locks를 조회해 보면 다음과 같이 locktype이 page인 Predicate Lock 1개만 조회된 결과를 볼 수 있습니다.

관련 파라미터 max_pred_locks_per_page를 확인해 보겠습니다.
SHOW max_pred_locks_per_page;
max_pred_locks_per_page
-------------------------
2해당 파라미터 정보가 나타내듯, 하나의 Page에 대하여 Predicate Lock을 2개로 제한하고 있으므로, Row 3개에 대하여 Predicate Lock이 필요한 경우 Lock Escalation이 발생하게 되고, 이로 인해 tuple이 아닌 page에 대한 Predicate Lock이 설정되었음을 알 수 있습니다.
📢 max_pred_locks_per_page 파라미터는 PostgreSQL ver.10 이후부터 사용자가 설정할 수 있습니다.
Lock Contention
Predicate Lock에 대한 이해를 바탕으로 동시 트랜잭션 상황에서 Predicate Lock의 동작 과정을 살펴보겠습니다.
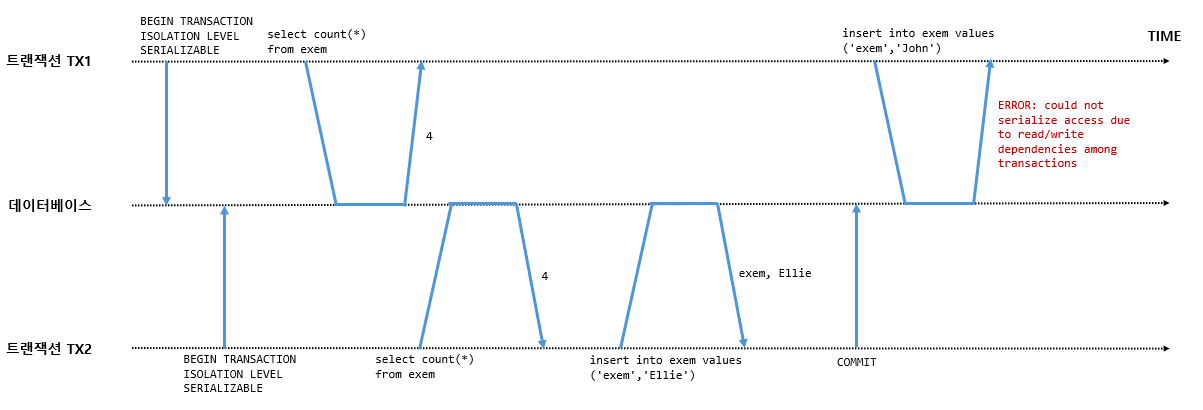
아래 예시에서는 Serializable Level의 격리 수준의 두 트랜잭션에서 Read와 Write 작업을 차례로 수행합니다. 두 트랜잭션 모두 Serializable Level이므로 Predicate Lock을 사용하여 두 트랜잭션 간 데이터 종속 관계를 모니터링합니다.
select * from exem;
group_name | name
-----------+-----+
exem | Zoey
exem | Lisa
exem | Tom
exem | Kai
| 트랜잭션 TX1 | 트랜잭션 TX2 | |
| t0 | BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
| t1 | select count(*) from exem; |
|
| t2 | select count(*) from exem; |
|
| t3 | insert into exem values('exem','Ellie'); |
|
| t4 | commit; |
|
| t5 | insert into exem values('exem','John'); |
테스트 결과, 트랜잭션 TX2는 Commit이 정상 수행되었지만, 트랜잭션 TX1은 아래와 같은 ERROR 메시지와 함께 Rollback 되었습니다.
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.
[t1] 트랜잭션 TX1은 테이블 exem에 대하여 Select command를 수행합니다. 이때 Predicate Lock을 사용하여 해당 데이터에 대한 종속 관계는 모니터링됩니다.
그 후 트랜잭션 TX2가 동일한 테이블 exem에 [t2] Read 작업을 수행하고, 이어서 [t3] Write 작업을 순차적으로 수행할 때도 Predicate Lock이 설정됩니다. 이때 다음과 같이 pg_locks를 조회하면 두 트랜잭션에 대하여 mode=SIReadLock조건을 통해 Predicate Lock이 설정된 것을 볼 수 있습니다.

그리고 [t4] 트랜잭션 TX2가 먼저 Commit을 수행, 정상 종료합니다. 데이터 종속 관계를 모니터링하기 위해서 Predicate Lock은 바로 해제하지 않습니다. 마지막으로 [t5] 트랜잭션 TX1이 Insert Command를 수행합니다. 하지만 TX1과 TX2 간 RW 충돌로 serialization anomaly에 해당하는 'write skew' 발생이 의심되는 상황으로, 이를 방지하기 위해 TX1에 ERROR 메시지를 표시하고 트랜잭션은 Rollback 처리됩니다.
Non-relation Lock
이번에는 Non-relation Lock에 대해 알아보도록 하겠습니다. Non-relation Lock이란 편의상 Relation을 제외한 모든 Object(Tablespcae, Schema, Role 등)에 대한 Lock을 통칭합니다. 이러한 Object Lock은 pg_locks에서 locktype=object로 조회 가능합니다.
예시를 통해 Object Lock을 확인해 보겠습니다.
CREATE TABLE example(n integer);새로운 테이블을 생성하는 Create Table Command를 수행한 후, pg_locks를 locktype=object 조건을 추가하여 조회하였습니다.
-- pg_locks 조회 (locktype=object)
SELECT database,
(SELECT datname FROM pg_database WHERE oid = database) AS dbname,
classid,
(SELECT relname FROM pg_class WHERE oid = classid) AS classname,
objid,
mode,
granted
FROM pg_locks
WHERE locktype = 'object'
AND pid = pg_backend_pid();
pg_locks 조회 결과를 보면, Create Table Command를 수행한 트랜잭션이 Object Lock을 획득했다는 것을 알 수 있습니다. pg_locks 조회 결과를 보면 classid와 objid는 대상 Object를 가리키는데, classid를 참조하여 pg_class를 조회하면 해당 Object에 대한 정보를 저장하고 있는 시스템 카탈로그 뷰(pg_class.classname)를 확인할 수 있습니다. Object Type에 따라 classname이 다르게 표시되며, classname을 추가 조회하면 Lock의 대상이 되는 Object를 특정할 수 있습니다.
예시에서는 classname이 pg_namespace이므로 Object Type이 Schema라는 것을 알 수 있습니다. 정확히 어떤 Schema에 대한 Lock 인지 확인이 필요한 경우, 다음과 같이 pg_namespace를 조회하여 대상을 확인할 수 있습니다.
-- select {object_name} from {classname} where oid=objid;
SELECT nspname FROM pg_namespace WHERE oid = 2200;
nspname
−−−−−−−−−
public위와 같이 pg_locks에서 확인한 objid를 pg_namespace의 oid에 대한 조건절로 확인해 보면, public Schema에 대한 Lock이라는 것을 알 수 있습니다. 이를 통해 새로운 테이블을 생성하는 작업은 해당 테이블이 생성되는 Schema에 대한 Lock이 필요하다는 것을 확인할 수 있습니다. 이렇게 획득한 Lock은 테이블을 생성하는 동안 다른 트랜잭션이 해당 Schema를 삭제하지 않도록 보호하는 역할을 합니다.
Non-relation Lock은 Relation을 제외한 Object를 대상으로 하기 때문에 그 대상이 매우 다양합니다. 때문에 정확한 대상을 확인하기 위해서는 pg_locks에서 확인한 classid와 objid를 바탕으로 시스템 카탈로그 뷰를 추가 조회해야 하며, 이러한 Non-relation Lock은 모두 대상 Object를 보호하기 위한 공통점을 갖습니다.
Relation Extension Lock
Relation 데이터가 저장되는 Page에 대하여 설정하는 Lock으로, 더 많은 공간이 필요하여 새로운 Page로 확장(Relation Extension)이 필요한 상황에서 사용합니다. Relation Extension Lock을 통해 여러 프로세스들이 같은 Page에 대하여 동시에 확장하지 못하게 관리할 수 있으며, HWLock 유형에 속하는 Lock으로, pg_locks에 locktype=extend로 조회할 수 있습니다.
- Relation Extension을 수행하고자 하는 프로세스의 개수에 영향을 받습니다. 프로세스 수가 증가할수록 설정 가능한 Relation Extension Lock의 수도 증가합니다. (단, 동시 작업 가능한 Page의 수는 512보다 작은 값이어야 합니다.)
📢 PostgreSQL ver.9.6 이전에는 Relation Extension Lock을 한 시점에 1개만 설정 가능했지만, PostgreSQL ver.9.6부터 이를 개선하여 한번에 여러 Page에 대한 Relation Extension이 가능하게 되었습니다.
- Relation Extension 작업이 종료되면 곧바로 Lock이 해제됩니다.
- 인덱스에 대한 Vacuum 수행 시, Data File에 새로운 Page가 추가되는 것을 막기 위한 용도로 사용될 수 있습니다.
Page Lock
Page Lock은 HWLock 유형에 해당하며, GIN 인덱스를 사용할 때 적용되는 Lock입니다.
GIN 인덱스를 사용하는 경우, Row를 추가하면 새로운 문자열을 Split 하여 lexeme을 생성한 후 이를 모두 GIN 인덱스에 Update 하는 작업을 수행해야 합니다. 추가되는 문자열의 크기가 클수록 Update 작업에 더 많은 시간과 메모리가 사용됩니다.
PostgreSQL에서는 GIN 인덱스 사용 시, pending list라는 배열을 사용합니다. 여러 개의 Row에 대하여 생성된 lexeme을 바로 GIN 인덱스에 Update 하는 대신, pending list에 정렬되지 않은 상태로 빠르게 추가합니다. 그리고 pending list에서 중복 제거를 한 후, 일괄적으로 GIN 인덱스에 Update 함으로써 GIN 인덱스의 Update 성능을 높였습니다.
하지만 pending list에서 GIN 인덱스로 Update하는 작업을 여러 프로세스가 동시에 수행한다면, 데이터 정합성이 위배될 수 있습니다. 이를 해결하기 위해 GIN 인덱스에 대하여 하나의 프로세스만 Update 작업을 허용(Exclusive Mode)하는 Page Lock을 사용하며, 획득한 Lock은 GIN 인덱스 Update 작업이 종료되면 즉시 해제됩니다.
📢 Page Lock은 pg_locks에서 locktype=page로 확인할 수 있습니다. 이전에 설명한 Predicate Lock의 경우도 Lock Escalation으로 인해 Tuple에서 Page로 Lock 범위가 확장되면 locktype에page가 표시될 수 있으나, 이 경우에는 mode가SIReadLock으로 한정됩니다.
Advisory Lock(User Lock)
사용자에 의해 명시적으로 획득되는 HWLock 유형의 Lock입니다. 주로 Application 상에서 사용자에 의해 의도적으로 Lock을 구현하고자 할 때 활용되며, 다른 말로 User Lock이라고 합니다. Advisory Lock은 pg_locks에서 locktype=advisory로 확인할 수 있습니다.
관련 함수
PostgreSQL에서는 Advisory Lock을 관리하기 위해 다음과 같은 함수를 제공하고 있습니다.
| 함수명 | 동작 |
| pg_advisory_lock | Advisory Lock을 획득함 |
| pg_advisory_lock_shared | Advisory Lock을 Shared Mode로 획득함 |
| pg_advisory_xact_lock | Advisory Lock을 획득한 후 트랜잭션이 종료될 때 해제함 |
| pg_advisory_xact_lock_shared | Advisory Lock을 Shared Mode로 획득한 후 트랜잭션 종료시 해제함 |
| pg_try_advisory_lock | Advisory Lock을 대기없이 획득 가능한 경우에만 획득함 |
| pg_try_advisory_xact_lock | Advisory Lock을 대기없이 획득 가능한 경우에만 획득하며, 트랜잭션이 종료될 때 해제됨 |
| pg_try_advisory_lock_shared | Advisory Lock을 대기없이 획득 가능한 경우 Shared Mode로 획득함 |
| pg_try_advisory_xact_lock_shared | Advisory Lock을 대기없이 획득 가능한 경우 Shared Mode로 획득하며, 트랜잭션이 종료될 때 해제됨 |
| pg_advisory_unlock | Advisory Lock을 해제함 |
| pg_advisory_unlock_shared | Shared Mode로 획득된 Advisory Lock을 해제함 |
| pg_advisory_unlock_all | 모든 Advisory Lock을 해제함 (해당 프로세스가 가지고 있는 Advisory Lock을 대상) |
사용 예시
가정 : 사용자가 현재 트랜잭션이 수정하고 있는 데이터를 다른 트랜잭션에서 읽지 못하게 할 목적으로 Advisory Lock을 사용합니다.
-- 테이블 adv
c1|c2 |
--+-------+
1|insert1|
2|insert2|먼저, 위와 같이 테스트 테이블을 생성하였습니다.
-- 트랜잭션 TX1
begin;
-- UPDATE 수행 + Advisory Lock
update adv
set c2='update1'
where c1=1
returning pg_try_advisory_xact_lock(c1);트랜잭션 TX1을 시작하고 Update Command를 수행하여 데이터를 수정합니다. 이때 pg_try_advisoty_xact_lock 함수를 통해 adv 테이블의 c1 컬럼에 트랜잭션 종료 시 해제되도록 함수를 사용하여 Advisory Lock을 설정하였습니다.
-- 트랜잭션 TX2
begin;
-- SELECT 수행
select *
from adv
where c1=1;
c1 | c2
----+---------
1 | insert1이어서 트랜잭션 TX2를 시작한 후, 트랜잭션 TX1이 수정 중인 데이터에 Read 작업을 요청하였으며, 해당 Select Command는 정상적으로 수행 완료됩니다.
-- 트랜잭션 TX2
select *
from adv
where c1=1
and pg_try_advisory_xact_lock(c1);
c1 | c2
----+----
(0 rows)마지막으로 동일 트랜잭션 TX2에서 Advisory Lock을 조건절에 추가하여 Read 하고자 하는 데이터의 Advisory Lock 설정 여부를 확인해 봅니다. 그 결과 TX1이 먼저 해당 데이터에 Advisory Lock을 설정한 후 수정 작업을 진행하고 있기 때문에, 트랜잭션 TX2는 데이터를 읽기 못하고 빈 결과를 리턴합니다(0 rows).
이처럼 Advisory Lock을 사용한다면 사용자는 원하는 대로 데이터 수정 또는 읽기를 제한할 수 있을 뿐만 아니라, 이를 활용해 트랜잭션 간 데이터 처리 순서도 제어할 수 있습니다.
Memory Lock
Memory Lock은 PostgreSQL의 Shared Memory 구조를 보호하는 Lock입니다. 일반적인 Lock의 유형인 HWLock과는 다른 특징을 가지며, 비교적 가벼우면서 적은 비용을 사용합니다.
LWLock (Lightweight Lock)
Shared Memory 내부의 다양한 영역을 보호하는 데 사용하는 Lock으로, BufferMapping Lock, BufferContent Lock 등 그 종류가 매우 다양합니다.
- Lock Mode는 두 가지를 제공하며, 데이터 수정에 사용하는 Exclusive Mode와 Read-only에 사용되는 Shared Mode가 있습니다.
- HWLock과 달리 Wait Queue를 구성하지 않습니다. 그렇기 때문에 Lock이 보호하는 Memory 영역에 여러 개의 프로세스가 Access 하는 경우, 무작위 순서로 해당 Lock을 획득합니다.
Buffer Pin
Shared Memory 구조 중에서 Buffer Descriptor 영역을 보호하는 Lock입니다.
📢 Buffer Descriptor는 Shared Memory 내에서 데이터를 저장하는 Shared Buffer 구성 요소 중 하나로, 저장하고 있는 데이터에 대한 메타 데이터 배열입니다.
- 프로세스가 Access 하고자 하는 Buffer Descriptor의 상태 정보를 pinned 또는 unpinned와 같이 표시하는 방식으로 동작합니다. (LWLock와 달리 Exclusive, Shared와 같은 Lock Mode를 제공하지 않습니다.)
- Select, Insert, Update 등 일반적인 SQL Command 수행의 경우, 2개 이상의 프로세스가 동시에 Buffer Pin을 설정할 수 있습니다.
- Shared Buffer 내의 데이터를 물리적으로 삭제나 변경하려는 경우, 해당 Buffer Descriptor에 Buffer Pin을 설정한 다른 프로세스가 없어야 합니다.
- 해당 Buffer Descriptor에 Buffer Pin을 설정하고자 하는 프로세스의 수를 Buffer Descriptor의 reference count라는 항목에 별도로 저장하여 관리합니다.
Spin Lock
LWLock과 Buffer Pin처럼 Shared Memory 내부에서 동작하는 Short-term Lock입니다. 하드웨어 atomic-test-and-set 지침을 사용하여 구현되었으며 매우 간단한 Atomic Operation이 Spin Lock의 대상입니다.
- Spin Lock은 획득할 때까지 획득 요청을 반복하면서 busy-loop 대기합니다.
- 1분 정도의 시간이 흐른 후에도 획득을 실패하면 TimeOut이 발생합니다.
- Spin Lock은 필요에 따라 LWLock, Buffer Pin의 동작 과정에 포함되기도 합니다. 주로 LWLock에 대한 인프라에 사용됩니다.
마무리
Relation-level, Row-level Lock에 이어서 PostgreSQL에서 제공하는 다양한 종류의 Lock에 대하여 알아보았습니다.
- Predicate Lock은 Serializable Isolation Level 사용 시 Serializability를 보장하기 위하여 사용되며, 필요에 따라 여러 개의 세분화된 Lock을 단일 Lock으로 Escalation 하는 특징을 갖는다.
- Non-relation Lock는 Relation을 제외한 Object를 보호하기 위한 목적으로 사용되는 Lock을 총칭한다.
- Relation Extension Lock은 새로운 Page로 물리적 확장 작업(Relation Extension)이 필요한 경우에 사용되는 Lock이다.
- Page Lock은 GIN 인덱스 컬럼에 새로운 문자열 Row가 추가될 때 사용되며, GIN 인덱스에 대하여 하나의 프로세스에 대해서만 Update 작업을 허용한다.
- Advisory Lock를 사용하면 사용자는 의도적으로 Lock을 설정하여 동작을 제어할 수 있다.
- Memory Lock은 Shared Memory의 각 영역을 보호하며 LWLock, Buffer Pin, Spin Lock 등의 유형을 제공한다.
이번 글을 마지막으로 PostgreSQL의 Lock을 주제 글은 모두 마치겠습니다.
이후에는 PostgreSQL의 내부 구조와 동작 방식을 설명하고, 그 과정에서 필요한 Lock과 그 Lock을 획득하는 과정에서 발생할 수 있는 Wait Event에 대해서 자세히 살펴보겠습니다.


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PWI - Shared Buffer > Wait Event (0) | 2024.11.27 |
|---|---|
| DB 인사이드 | PWI - Shared Buffer > 동작원리 (0) | 2024.10.25 |
| DB 인사이드 | PWI - LOCK > Row-level Lock(2) (0) | 2024.08.05 |
| DB 인사이드 | PWI - LOCK > Row-level Lock(1) (0) | 2024.08.05 |
| DB 인사이드 | PWI - LOCK > Relation-level Lock (0) | 2024.06.11 |




댓글